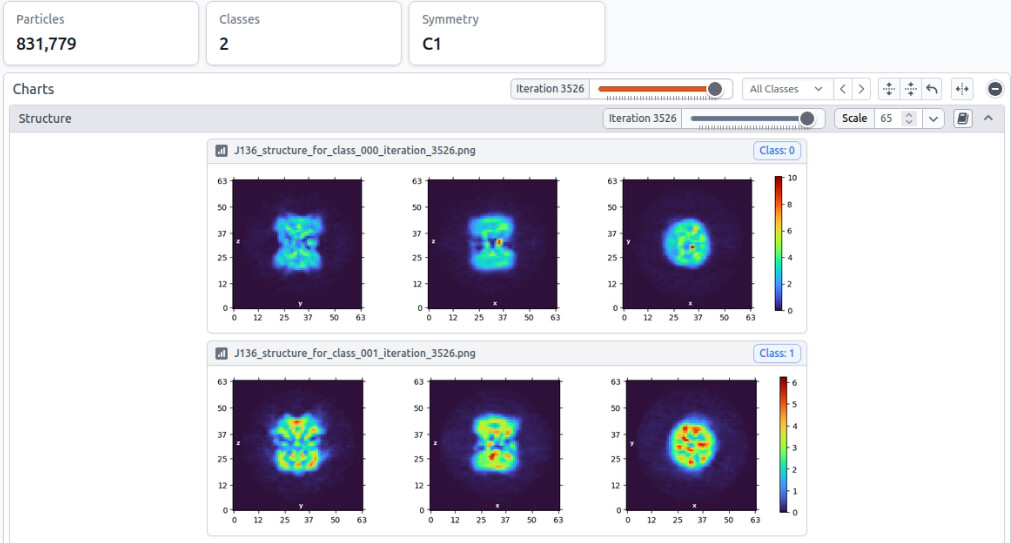
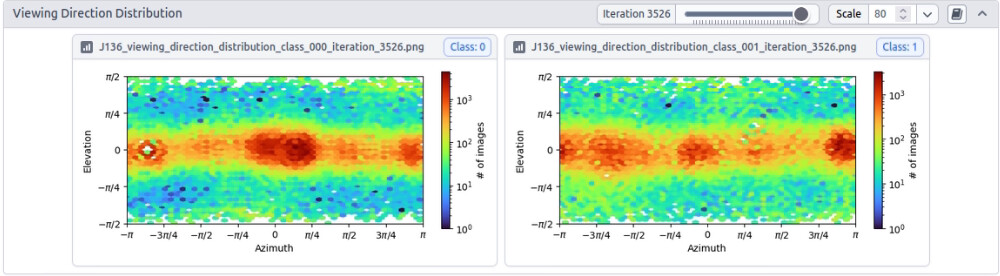
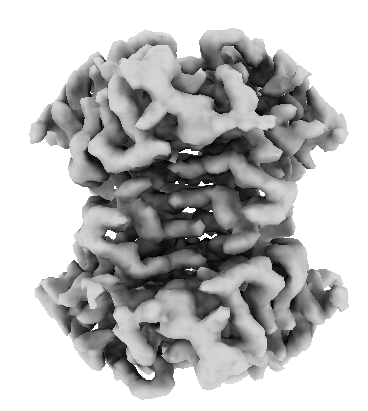
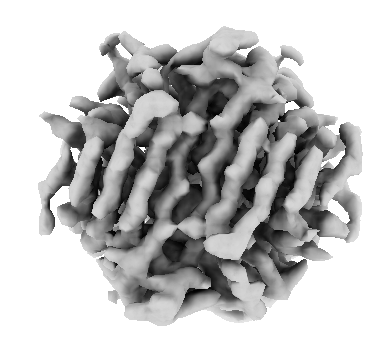
I’m trying to solve the structure of streptavidin bound to a ligand. Data was collected on 300 kV Krios Gatan K3 detector at pixel size of 0.65 A.
After several rounds of 2d classification we were able to get clean set of 2d classes (831779 particles) using following parameters: clamp-solvent- ON, no.of online-EM iterations 40, Batch size- 400, enforce negativity- ON.
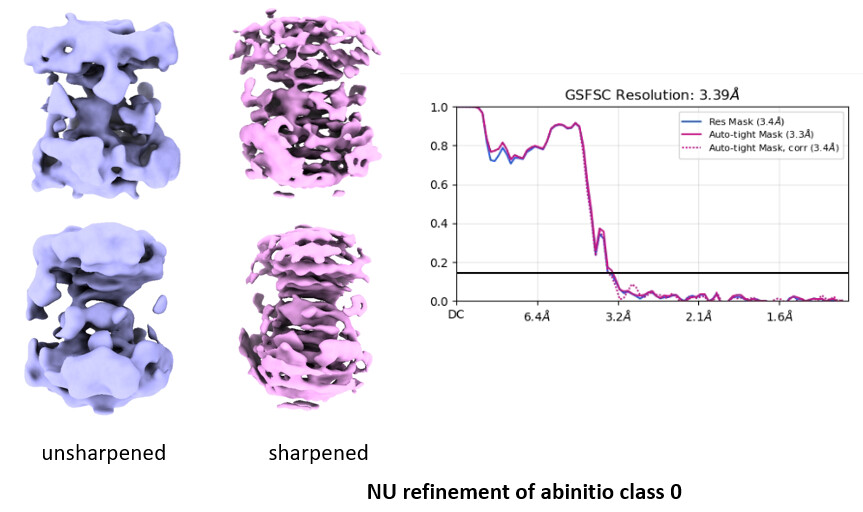
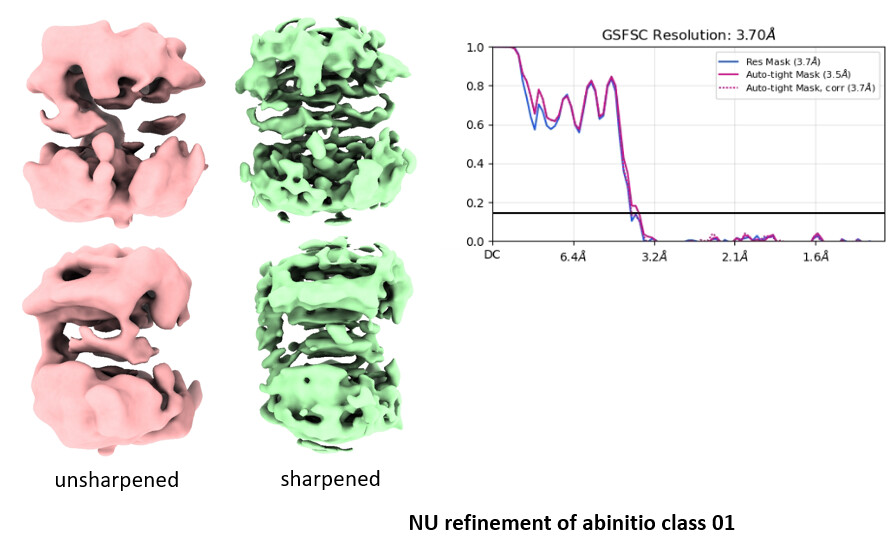
Both the abinitio model were refined independently (after re-extracting with box size 196 px) using NU refinement (default settings except dynamic mask was kept off).
I would like to ask if there are any additional ways to improve my map (other than collecting more data to minimize orientation bias). All suggestions would be greatly appreciated. Please let me know if you require any further information
Thank you
Have you taken a look at @olibclarke ‘s recent biorxiv paper on small particle reconstructions via ab-initio? CS v5 specifically has half-sets included in ab-initio now so that this protocol can be used rigorously. Folks I work with have had good success with it so far with proteins around your size.
You can try doing a local refinement as well with masking the entire protein, sometimes that can improve resolution. What does your mask look like and did you try with the new dynamic masking on? I can’t quite tell if your particle contains symmetry, but are you imposing symmetry if so? Have you tried 3D classification and/or heterogeneous refinement to separate out what may be different classes? Is all of this with approximately 831k particles?
you are using multi-class ab initio to separate your particles. I would use it instead to generate decent volumes, but then move forward again with all particles. as talya suggested above use HR-HAIR but also consider one-class ab initio. generate some decoys and perform het refine with 1 good volume 3 decoys, trying each “good volume” from several ab initio runs independently. 3D classification with resolution 4 or 6 or 8 and the rest of the tricks to force sorting. Even though the particle is quite small and many of these steps will be more difficult to get to work well, you can and should still try more than 2D→initio→refine.
Another thing to try would be rebalance the particle alignments and try re-doing ab initio without such an extreme bias for a single view. Once a good initial model and refinement are there you can try slowly adding back views (change percentage of rebalance job) until the anisotropy hits again.
I realize I did not describe my exact processing pipeline earlier, so I am outlining it here in detail.
I performed motion correction, CTF estimation, and micrograph denoising. I initially carried out blob picking (60–80 Å) on a few micrographs, followed by particle extraction (192 px box size, Fourier-cropped to 48 px). After 2D classification, I used the good-looking classes for template-based picking across the entire dataset. I then removed junk particles through several rounds of 2D classification.
Next, I performed multi-class ab initio reconstruction using the good classes, and a separate multi-class ab initio using the bad 2D classes to generate decoy classes for further particle cleaning during heterogeneous refinement. I used one good and three bad ab initio classes in heterogeneous refinement. Particles from the good class were then extracted at full box size and subjected to non-uniform (NU) refinement; however, the resulting map was not satisfactory. The density appeared broken, and the map looked distorted (compressed and stretched).
I suspected that some bad particles were still present. Therefore, I performed manual curation and removed micrographs with a CTF fit resolution worse than 4 Å. I then carried out another round of 2D classification on the remaining particles, applied very stringent selection criteria, and ended up with 831,779 particles (as shown earlier).
Using these particles, I again performed a two-class ab initio reconstruction followed by NU refinement. However, I obtained essentially the same result, with a distorted (stretched/compressed) map. I also performed 3D classification, however, it did not lead to any improvement
very helpful info. thanks. did you try D2 symmetry during any step? If you are using ab initio result as input reference for NU-refine, then it just seems like it’s having a hard time with maximization and building a better structure. could you use a published streptavidin reference (generally I wouldn’t do this) or apply symmetry if it exists to eliminate distortion such that NU-refine will more appropriately assign particles, enabling better maximization?
I went through @olibclarke ‘s HR-HAIR paper and applied the approach to my particles. I was unable to obtain a decent reconstruction at a 192 px box size; however, after re-extracting the particles at 384 px and Fourier-cropping to 192 px, I was able to obtain a very clean and interpretable class. This approach also appeared to reduce the anisotropy that was evident in the 2D classes.
Applying inner/outer windowing did not make any noticeable difference to the reconstruction. However, when a window radius was applied, the job took ~34 hours to complete on an A4000 GPU (772,228 particles), whereas without any mask/window radius, the job completed in ~18 hours.
This is fantastic. If I understand correctly, the box that worked makes almost 3 times the size of the particle, is that correct? Reminds me of an old publication where they were suggesting 2.5X box/particle but it never worked for me. We rarely talk about box sizes, it seems that it can be relevant sometimes, and I don’t think 2.5-3X are on the usual ranges for most people.
It depends on particle size (how big to make it as a multiple of the particle size I mean), as well as on defocus and kV - Look up JMB 2003 Rosenthal & Henderson for a good explanation.
Basically the smaller the particle (and the higher the defocus and the lower the kV), the larger the box size you will need to capture delocalized information at a given resolution.
True. The publication (actually pre-print) I was thinking about is this one: https://doi.org/10.1101/2020.08.23.263707 ; despite all, I’ve seen cases where a very narrow box (1.2 X) was giving better resolution - maybe there are variations in image quality related to defocus? After this, I ended up by simply trying different box sizes to try to find a trend, and that for each data collection that I think deserves the work.