Hi, I have a couple of more questions about 2D classification jobs. I am running 4.0.1 version as well, have 4 RTX 2080 TI GPUs, used two of them for the job. Got an error message:
[CPU: 15.73 GB]
Traceback (most recent call last):
File “/mnt/ape2/cryosparc/software/cryosparc/cryosparc_worker/cryosparc_compute/jobs/runcommon.py”, line 1925, in run_with_except_hook
run_old(*args, **kw)
File “cryosparc_worker/cryosparc_compute/engine/cuda_core.py”, line 131, in cryosparc_compute.engine.cuda_core.GPUThread.run
File “cryosparc_worker/cryosparc_compute/engine/cuda_core.py”, line 132, in cryosparc_compute.engine.cuda_core.GPUThread.run
File “cryosparc_worker/cryosparc_compute/engine/engine.py”, line 1028, in cryosparc_compute.engine.engine.process.work
File “cryosparc_worker/cryosparc_compute/engine/engine.py”, line 107, in cryosparc_compute.engine.engine.EngineThread.load_image_data_gpu
File “cryosparc_worker/cryosparc_compute/engine/gfourier.py”, line 32, in cryosparc_compute.engine.gfourier.fft2_on_gpu_inplace
File “/mnt/ape2/cryosparc/software/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/fft.py”, line 134, in init onembed, ostride, odist, self.fft_type, self.batch) File “/mnt/ape2/cryosparc/software/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py”, line 749, in cufftMakePlanMany cufftCheckStatus(status)
File “/mnt/ape2/cryosparc/software/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py”, line 124, in cufftCheckStatus raise e
cryosparc_compute.skcuda_internal.cufft.cufftInternalError.
That never happened before the upgrade.
Also, and I have seen that before, sometimes classes display fails to set-up histogram properly, in some cases (attached) it is all black, or could be all white without any grey levels.
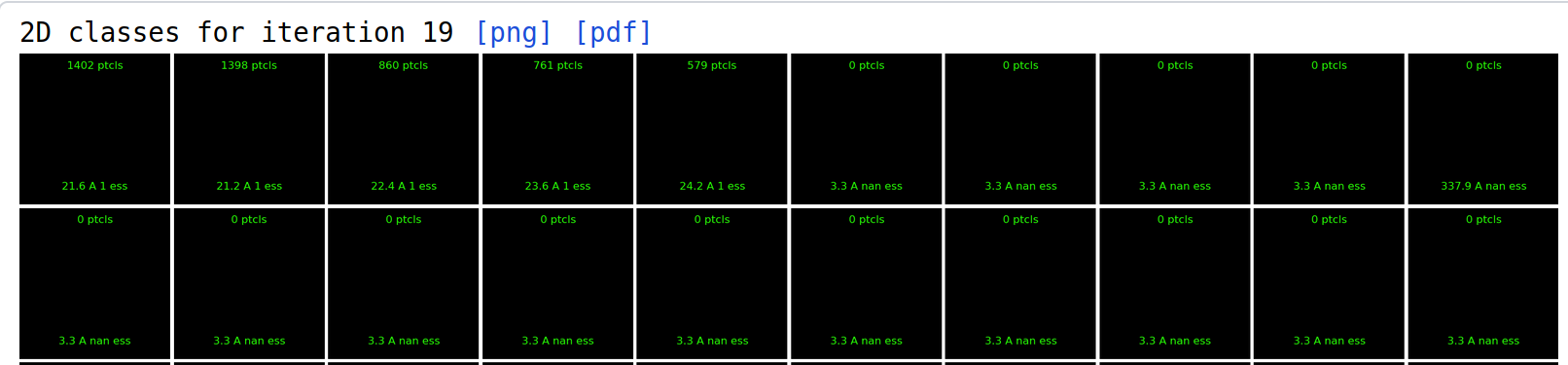
At the same time the side display window shows reasonable image:

. During that particular run, the main display window changed from normal grey level display to all white, then to all black, back and forth.
Like in @MichaelZ case, it is a dedicated headless cryosparc station.
Thanks,
Michael
