Hi All, I was using RTX 2080 and CryoSPARC v2.15.0 to do Local Refinement, got the following error. It seemed the memory is not enough according to the forum. Then I switched back to v2.13.2 and the Local Refinement job seems to be working fine at this moment although not done yet. Any suggestions? Thanks.
[CPU: 15.75 GB] -- DEV 0 THR 1 NUM 118150 TOTAL 538.02333 ELAPSED 2103.0518 --
[CPU: 23.47 GB] Processed 944598 images in 2111.028s.
[CPU: 24.81 GB] Computing FSCs...
[CPU: 26.45 GB] Done in 122.601s
[CPU: 26.45 GB] Using Filter Radius 79.205 (6.642A) | Previous: 26.304 (20.000A)
[CPU: 31.83 GB] Local decomposition...
[CPU: 42.28 GB] Traceback (most recent call last):
File "cryosparc2_compute/jobs/runcommon.py", line 1685, in run_with_except_hook
run_old(*args, **kw)
File "cryosparc2_worker/cryosparc2_compute/engine/cuda_core.py", line 110, in cryosparc2_compute.engine.cuda_core.GPUThread.run
File "cryosparc2_worker/cryosparc2_compute/engine/cuda_core.py", line 111, in cryosparc2_compute.engine.cuda_core.GPUThread.run
File "cryosparc2_worker/cryosparc2_compute/jobs/local_resolution/run.py", line 791, in cryosparc2_compute.jobs.local_resolution.run.standalone_locres.work
File "/data/donghua/cryosparc/cryosparc2_worker/deps/anaconda/lib/python2.7/site-packages/skcuda/fft.py", line 127, in __init__
onembed, ostride, odist, self.fft_type, self.batch)
File "/data/donghua/cryosparc/cryosparc2_worker/deps/anaconda/lib/python2.7/site-packages/skcuda/cufft.py", line 742, in cufftMakePlanMany
cufftCheckStatus(status)
File "/data/donghua/cryosparc/cryosparc2_worker/deps/anaconda/lib/python2.7/site-packages/skcuda/cufft.py", line 117, in cufftCheckStatus
raise e
cufftAllocFailed
Hi @donghuachen ,
Thanks for reporting this. I would agree that this looks like an out-of-memory issue, which can sometimes happen if you’ve used a very large box size, or if zombie processes holding up resources on the GPU. If there are no zombie processes on the GPU that you are using, could you confirm what the box size is that you are using? If the box size is greater than around 400, could you see if reducing the box size allows the job to run? This can be done by first passing the input particle stack through a “Downsample Particles” job, and setting the “Fourier crop to box size (pix)” parameter to any size below, and using these downsampled particles for the Local Refinement.
Best,
Michael
Hi Michael, Thanks for your reply. I was using the box size 480 and no zombie process. I have not tried Downsample because it may limit the resolution.
BTW, without Downsample, v2.13.2 worked on the same dataset for Local Refinement.
Hi @donghuachen,
Thank you for the clarification. In the local refinement job on v2.15.0, it looks like the job was run with NU-refinement enabled. Did that differ from the past working local refinement jobs on v2.13.2? With NU-refinement, the memory requirement is increased due to the extra regularization, so having this parameter differing between runs could be one possible explanation for running out of memory. If it was disabled on the jobs you ran in v2.13.2, could you see if the problem still persists when you disable it on v2.15.0?
In terms of downsampling particles, only if the original job on v2.13.2 was hitting the Nyquist frequency (or close to it) would downsampling the particles limit the resolution. You can examine if this is the case by downsampling the particles to box size ~400, for example, and then running another local refinement – if the non-zero Fourier-space voxels extend out right to the box edge, then that would indicate that resolution may be limited by the box size.
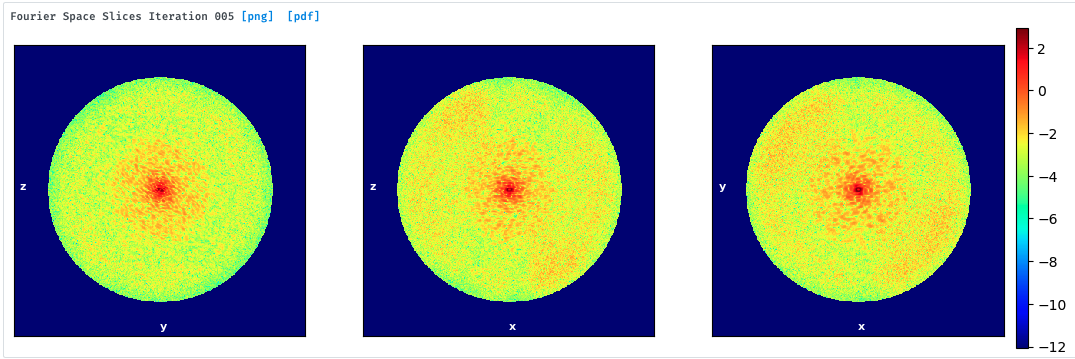
For example, in this recent local refinement I ran, the final structure reached 3.64 A resolution, and from the final Fourier-space slices, Fourier amplitudes only extend out to ~4/5 of the box size – in this case, downsampling particles to >=80% of their original size would still allow the refinement to achieve the same resolution.
I hope this helps, and best regards,
Michael
Hi Michael,
I did enable the option of NU Refinement for v2.13.2 Local Refinement on the same dataset and the job finished normally. Not sure why v2.15.0 failed on it.
Maybe as you suggested, I can downsample the subtracted particles from 480 to 400 to run v2.15.0. I have not tried yet.
Greatly appreciated your details about downsampling.
1 Like
Hi Michael,
I just tried to downsample my particles from 480 to 400 for box size, then I did NU Refinement and Particle Subtraction, followed by Local Refinement using v2.15.0. I got the same error as mentioned above. Any suggestions will be greatly appreciated!
Hi @donghuachen,
Just to confirm, are you running the local refinement job on a GPU that has no other ongoing processes using memory? Before running the local refinement job, you can run a nvidia-smi command to ensure that the memory usage on the GPU is in fact 0 MiB. If this is the case, does the error still persist during local resolution computation?
Finally, if the error is still there on v2.15.0, does downgrading to v2.13.2 and running the job on the same GPU (and otherwise under the same conditions) work?
Best,
Michael
Hi Michael,
There was no other job running except my cryosparc Local Refinement job. v2.15.0 with NU Refinement option ON failed on Local Refinement for the particles with both 480x480 and 400x400 box size, however, v.13.2 with NU Refinement option ON succeeded for Local Refinement for the particles with 480x480 box size (I guess v2.13.2 should succeed for the downsample 400x400 box size).