We have a cluster installation of the latest cryosparc (v3.2.0+210601) with 4 workers connected through InfiniBand.
For some reason, cryosparc jobs involved SSD cache would fail after a long SSD cache.
Below is the output of a recent heterogeneous refinment job.
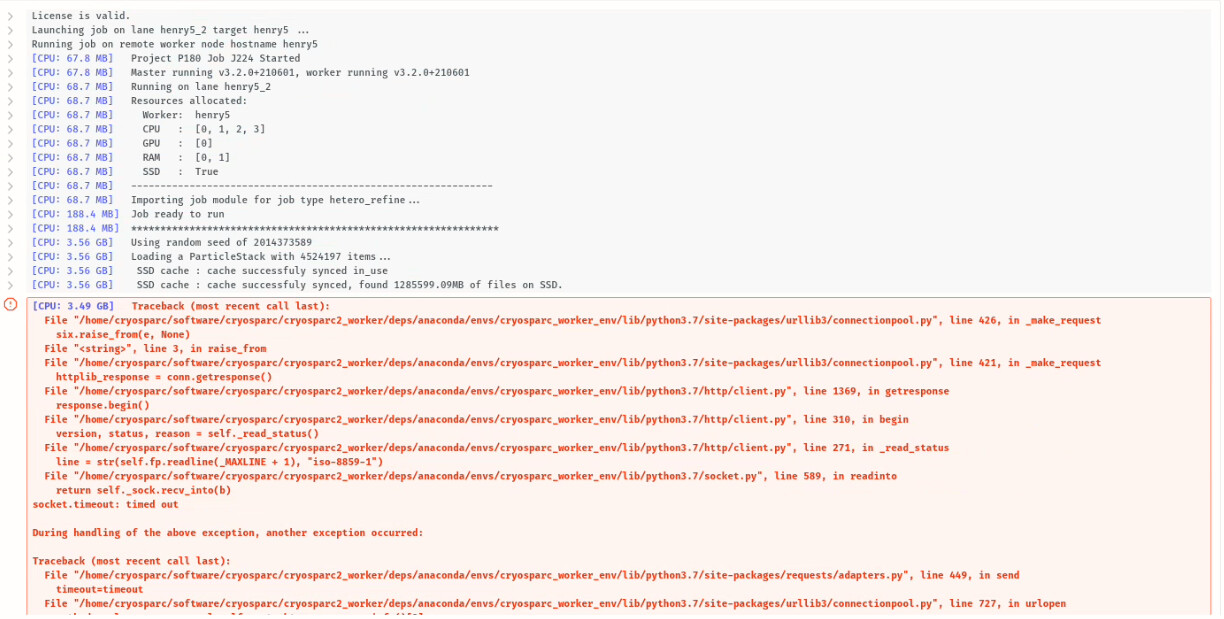
Basically, after cryosparc found 1.2 TB cache, the job stalled for 15 minutes before stopping with a read timeout error. Any idea why cryosparc stalled?
The cryosparcm joblog output is pasted below. Any suggestion or advice is welcomed.
================= CRYOSPARCW ======= 2021-07-05 15:24:43.320515 =========
Project P180 Job J224
Master henry4.ohsu.edu Port 39002
===========================================================================
========= monitor process now starting main process
MAINPROCESS PID 309070
MAIN PID 309070
hetero_refine.run cryosparc_compute.jobs.jobregister
========= monitor process now waiting for main process
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
***************************************************************
Running job J224 of type hetero_refine
Running job on hostname %s henry5
Allocated Resources : {'fixed': {'SSD': True}, 'hostname': 'henry5', 'lane': 'henry5_2', 'lane_type': 'henry5_2', 'license': True, 'licenses_acquired': 1, 'slots': {'CPU': [0, 1, 2, 3], 'GPU': [0], 'RAM': [0, 1]}, 'target': {'cache_path': '/henry5/scratch2/cryosparc/', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'hostname': 'henry5', 'lane': 'henry5_2', 'monitor_port': None, 'name': 'henry5', 'resource_fixed': {'SSD': True}, 'resource_slots': {'CPU': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31], 'GPU': [0, 1, 2, 3], 'RAM': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]}, 'ssh_str': 'cryosparc@henry5', 'title': 'Worker node henry5', 'type': 'node', 'worker_bin_path': '/home/cryosparc/software/cryosparc/cryosparc2_worker/bin/cryosparcw'}}
*** client.py: command (henry4.ohsu.edu:39002/api) did not reply within timeout of 300 seconds, attempt 1 of 3
*** client.py: command (henry4.ohsu.edu:39002/api) did not reply within timeout of 300 seconds, attempt 2 of 3
*** client.py: command (http://henry4.ohsu.edu:39002/api) did not reply within timeout of 300 seconds, attempt 3 of 3
**** handle exception rc
set status to failed
========= main process now complete.
========= monitor process now complete.