When we try to use Topaz train in the CryoSPARC GUI, the GUI frequently becomes laggy and unresponsive - buttons do not respond, jobs take longer to start, etc. Is this someone other people have encountered, and if so are there any tips for resolving it? Topaz doesn’t seem to be using an exorbitant amount of RAM, and although the CPU utilization is high it doesn’t look out of the ordinary.
(actually trying it now - it is not just cryoSPARC that becomes laggy and unresponsive, it is the system as a whole - e.g tab-completion on the command line becomes much slower, for example)
Can you try running Topaz as a standalone executable and observing if similar performance problems arise? It is possible that file system transfers in Topaz may have slowed down due to another process working on the cluster.
For example - while running a Topaz extract job, clearing or killing other jobs, or dragging inputs onto other jobs becomes nearly impossible, with extreme lag
Will do. Interestingly if I clone a previously completed Topaz extract job and run that, I do not see the lagginess - I guess something is being cached somehow?
The reason why cloning a job and re-running is different is because Cryosparc saves pre-processed images, so ‘topaz preprocess’ doesn’t need to be run again. This tells me that the problem you are having is likely from ‘topaz preprocess’. Can you try running a new job and reducing the ‘Number of parallel threads’ in the ‘Preprocessing parameters’ section of Topaz Train? It may just be that your CPU cache is hitting its limit, thus not letting other instructions run.
I think that is it… also the preprocessing seems to take the vast majority of the time for Topaz extract… if I run Topaz extract on 2200 mics, it takes ~2hrs, if I re-run it with same mics but different model (avoiding pre-processing), it takes 5min.
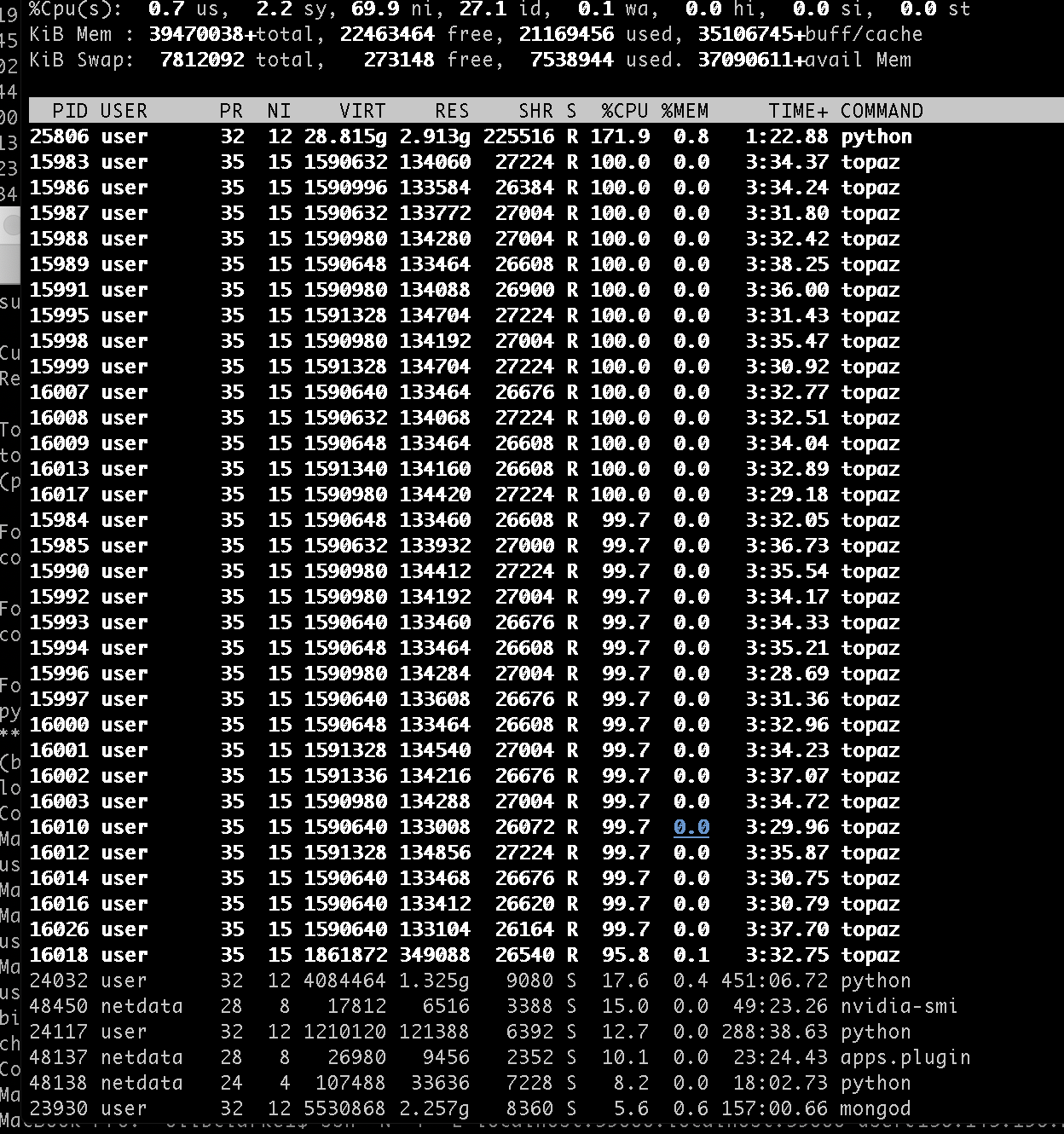
@stephan there was nothing informative in the command_core log, however I do notice that topaz seems to be using way more threads than I ask for - for example this is the output of top during a topaz train job where I asked for 4 parallel threads:
It seems like it is launching [number of threads] X [number of workers] individual topaz processes - @alexjamesnoble is this what is supposed to happen? maybe this is why it is slowing down so much? It seems like there is no way to control the num-workers param in cryoSPARC
It seems that [number of threads] X [number of workers] individual processes is intended. The [number of threads], controlled by the “Number of parallel threads” parameter simply spawns more instances of the preprocessing command except with different micrographs to preprocess. Once the instance is spawned, Topaz seems to run [number of worker] of its own processes. The “num-workers” parameters from Topaz can be controlled in cryoSPARC using the “Number of CPUs” parameter. This is the same parameter name used by the Topaz GUI to control the num-workers parameter.
@jyoo - Ok I see! The “Number of CPUs” parameter is right next to a slider switching between CPU and GPU, making it unclear (at least to me) that this pertains to runs where one is using only the GPU.
Also the “Number of CPUs” parameter is under “training parameters” but it is used during preprocessing - maybe it would be better moving it up adjacent to the “number of threads” parameter so this is clearer?
I do agree that it is unclear what the number of CPUs parameter does exactly. Moving the parameter could be a more effective way of communicating what the parameter does but the parameter name itself may warrant a change as well.
Hope this helps with your lag and unresponsiveness you’ve been experiencing.
Hi @jyoo - it does - I would also suggest altering the defaults. E.g. for Topaz extract the defaults are 8 workers with 8 threads each, meaning it spawns 64 (!) topaz processes, which is going to make most systems feel a bit laggy…
@jyoo one other thing - Topaz extract and train seem to skip preprocessing if a job is cloned and re-run, making things much faster. However this is only true if no parameters are altered. For testing different training parameters in particular it would be handy if Topaz train was configured to just use the cached preprocessed mics unless the micrograph input or downsampling has been changed, I think.