Same error using Muti-GPUs. Jobs can be finished when I used only one GPU.
And I can’t select the specific GPU.
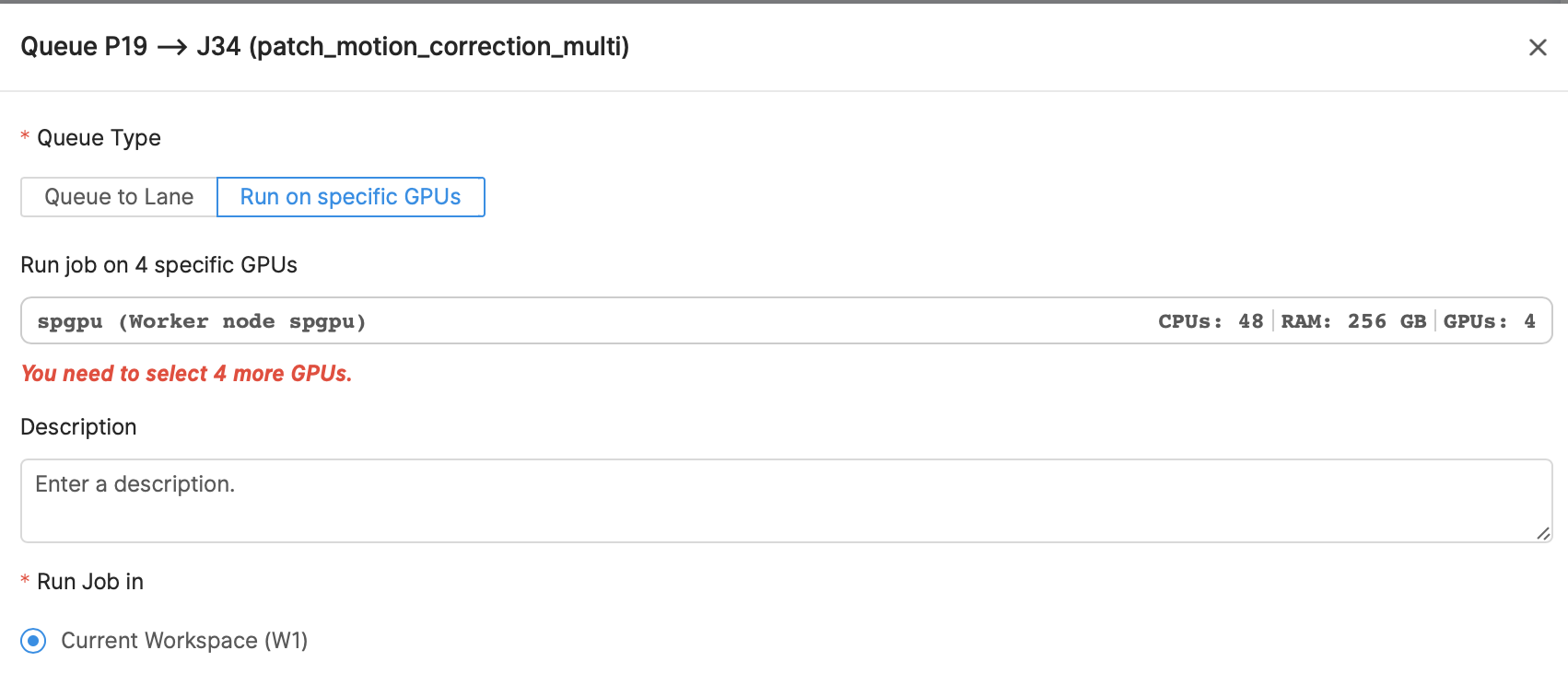
Hi @FengjiangLiu,
It seems like you can’t select a specific GPU because the GPU information is not populated in the database. The function that populates this information auto-runs when you start cryoSPARC. If for some reason the function fails, it will fail silently. You can re-run the function itself and decode the error logs (by monitoring cryosparcm log command_core).
In a shell, run: cryosparcm cli "get_gpu_info()" && cryosparcm log command_core
You might see a traceback- if you know what the problem is, go ahead and fix it, otherwise post it here and I can suggest some next steps.
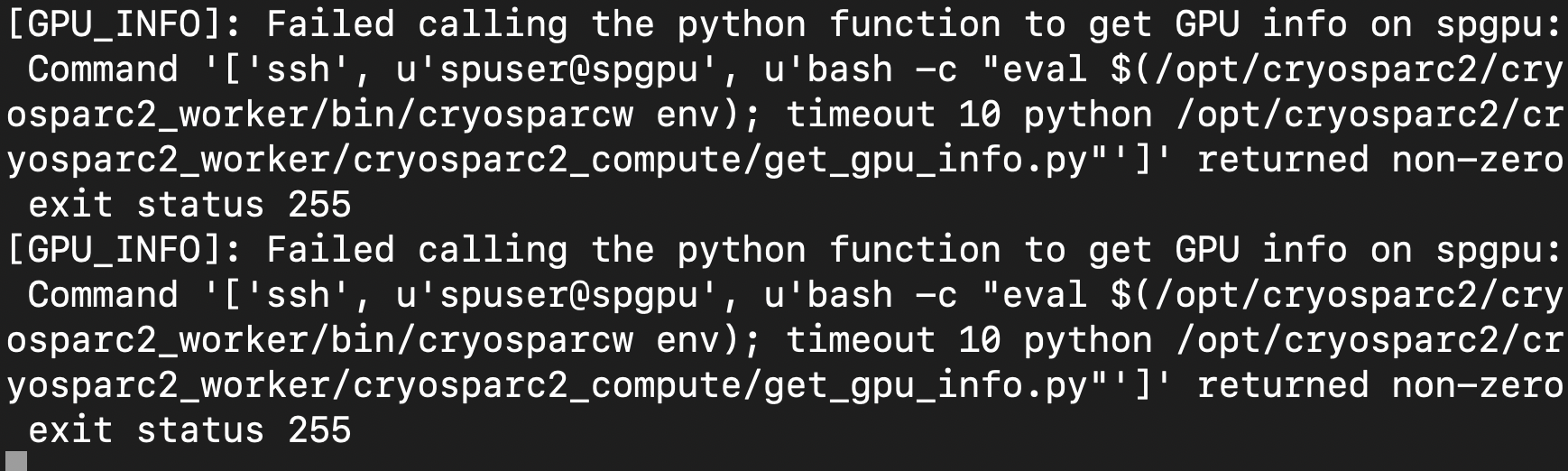
Hi @FengjiangLiu,
Looks like some sort of SSH error. From that machine, if you run ssh spuser@spgpu, do you get a Host Verification request? Or any other type of error?
Hi, @stephan
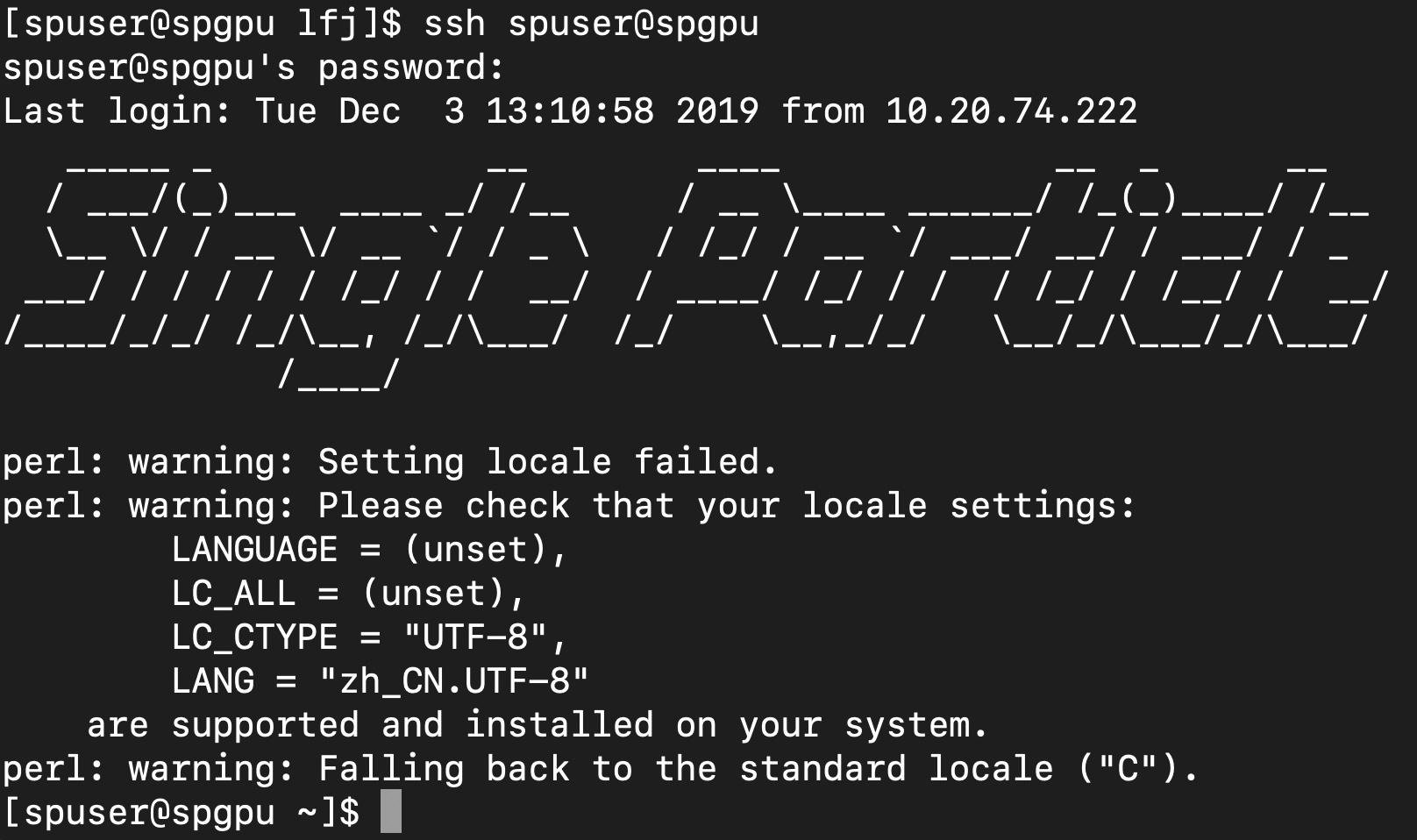
Just as same as former.
I noticed that when I upgrade cryoSPARC, many old software were upgraded too. If it is possible that something was changed about GPU or GPU detection.
Hi @stephan
I got the same problem on my ‘standalone’ machine. the sshuser@hostname can lead to the verification request.
Hi @FengjiangLiu,
You need password-less SSH access to this machine for the function to work properly.
Ensure that SSH keys are set up for the cryosparc_user account to SSH between the master node and the worker node without a password. From https://cryosparc.com/docs/reference/install/#remote-access:
Set up SSH keys for password-less access (only if you currently need to enter your password each time you ssh into the compute node).
-
If you do not already have SSH keys generated on your local machine, use
ssh-keygento do so. Open a terminal prompt, and enter:ssh-keygen -t rsa -N "" -f $HOME/.ssh/id_rsaNote: this will create an RSA key-pair with no passphrase in the default location.
-
Copy the RSA public key to the remote compute node for password-less login:
ssh-copy-id remote_username@remote_hostnameNote:
remote_usernameandremote_hostnameare your username and the hostname that you use to SSH into your compute node. This step will ask for your password.
Hi @hxn,
Thanks for reporting this. We’ll add a fix to ensure SSH is not used on standalone instances.
Hi @ sarulthasan
I can select a specific GPU now. Thanks a lot.
But there is still a problem in using Muti-GPUs in Patch Motion Correction.
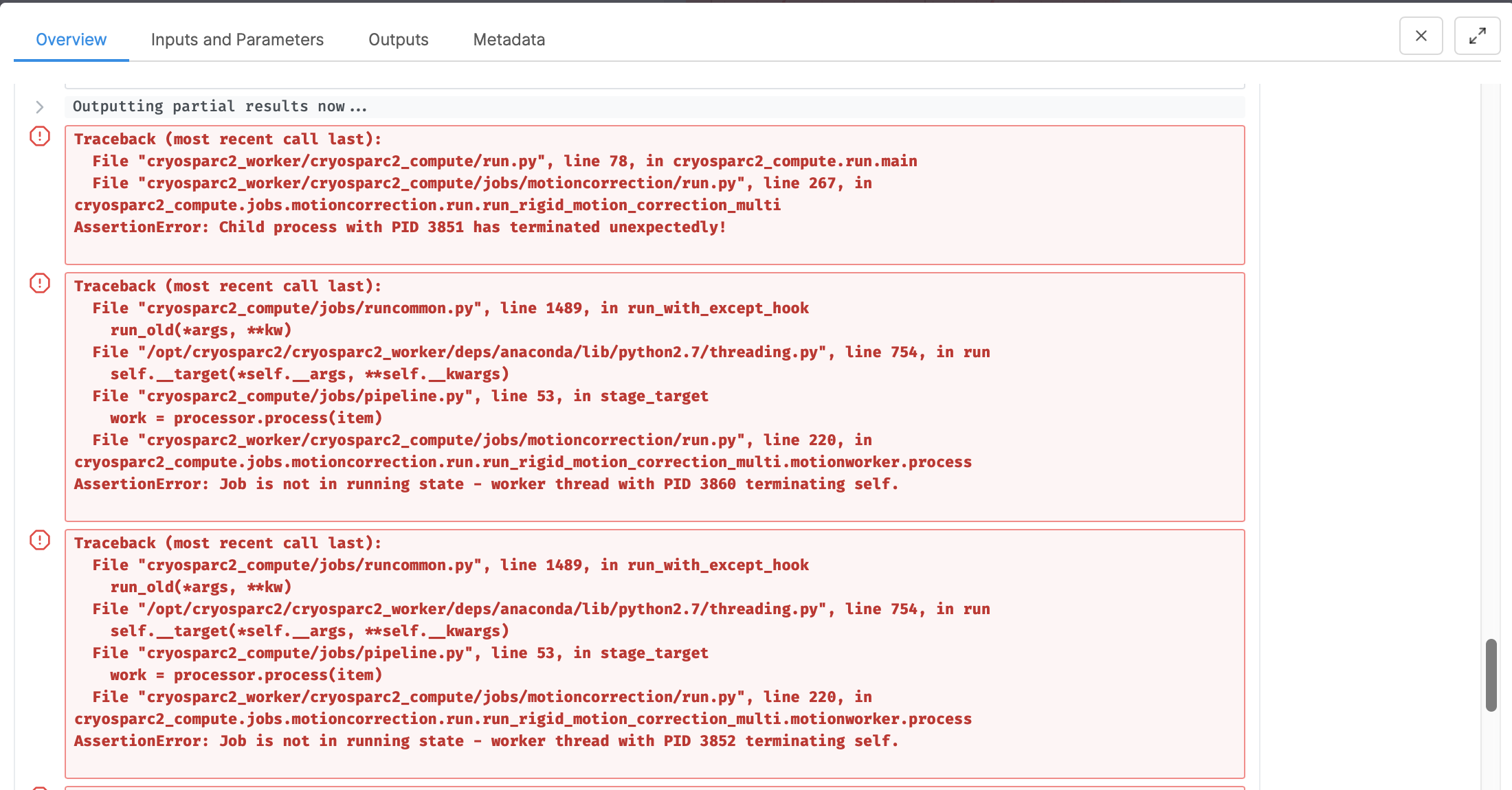
And when I ran “cryosparcm cli “get_gpu_info()” && cryosparcm log command_core”, the output shows like this.
Hi @FengjiangLiu,
Glad you were able to get the GPU queuing to work. Regarding the other error, it was a bug in cryoSPARC v2.12.0 and 2.12.2. A patch has been released (v2.12.4) to fix this issue, as well as a few others. To update, run cryosparcm update
Thank you very much! I’m going to try!
Hey,
unfortunately this solution also doesn’t work. We have a single master/worker workstation and the ssh also fails to connect on the same machine. I tried to pair ssh keys but no success. Always shows:
[GPU_INFO]: Failed calling the python function to get GPU info on witcher: Command ‘[‘ssh’, u’dawid@witcher’, u’bash -c “eval $(/mnt/data1/cryosparc2/cryosparc2_worker/bin/cryosparcw env); timeout 10 python /mnt/data1/cryosparc2/cryosparc2_worker/cryosparc2_compute/get_gpu_info.py”‘]’ returned non-zero exit status 255
for all gpus.
Best,
Dawid
Hi @dzyla,
So if you ensured that running ssh dawid@witcher directly doesn’t raise a Host Key Verification question/error, can you go ahead and try to run the following commands from the master node:
eval $(cryosparcm env)
ssh dawid@witcher bash -c “eval $(/mnt/data1/cryosparc2/cryosparc2_worker/bin/cryosparcw env); timeout 10 python /mnt/data1/cryosparc2/cryosparc2_worker/cryosparc2_compute/get_gpu_info.py”
You will probably see the actual error more clearly.
Thanks a lot, it helped to find the error. The problem is with the ssh command. The command you suggested finishes with error because the ssh command is not run, but instead the local command is run. I modified to command and now it works:
ssh dawid@witcher ‘bash -c eval $(/mnt/data1/cryosparc2/cryosparc2_worker/bin/cryosparcw env); timeout 10 python /mnt/data1/cryosparc2/cryosparc2_worker/cryosparc2_compute/get_gpu_info.py’
[{“mem”: 12788498432, “id”: 0, “name”: “TITAN Xp”}, {“mem”: 12788498432, “id”: 1, “name”: “TITAN Xp”}, {“mem”: 12788498432, “id”: 2, “name”: “TITAN Xp”}, {“mem”: 12788498432, “id”: 3, “name”: “TITAN Xp”}]
Is it possible to fix the previous command:
cryosparcm cli “get_gpu_info()” && cryosparcm log command_core
to update the number of GPUs on each node? This would be great!
Hi @dzyla,
Thanks for pointing this out, we’ve fixed this in our current release branch. You will receive this fix in an update to cryoSPARC soon!