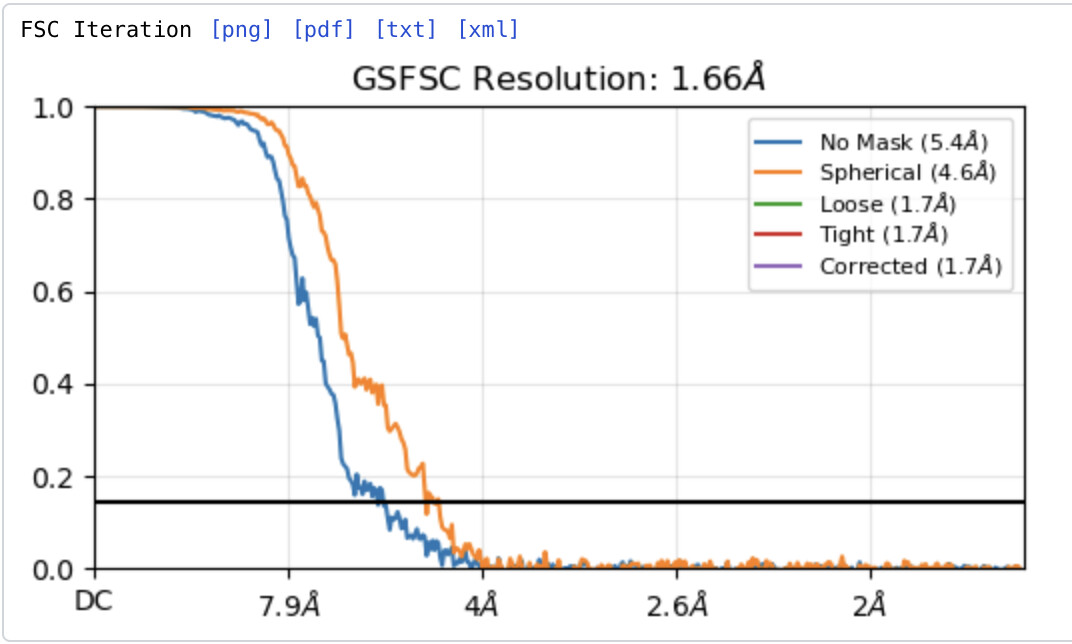
Hello @vperetroukhin,
Thank you for the reaction. I will try to describe my pipeline the best possible.
Starting particle stack: 421 677 ptc, extraction box 400 px downsampled to 128 px.
I did Ab initio (Job 380) with 6 classes. This job ran without any errors.
Then I took all particles from Job 380 and ran Heterogeneous refinement (Job 381) with 7 initial volumes taken from Job 380 and one volume from a previous Ab initio job. Two of the used volumes were good and five were junk. I set batchsize 3000 and refinement box size 64 vox. However, at the step where 21 000 particles were used, I got the error saying that 500 particles have NaN. When I reran this job later as Job 389 (I overwrote the original Job 381 with Hetero ref. for class 1 only, see below), it crashed with the same error already during iteration 0 before the numbers of particles assigned per class were available.
Hoping that those NaN particles might be only in some classes of the Job 380 Ab initio job, I did the same Heterogeneous refinement (same input volumes, box size and batchsize 3000) for each class of Job 380 separately:
Job 381 – particles from Job 380 class 1, total 58 183 ptc; ran successfully, final assignments per class: 0 – 8 533 ptc, 1 – 6 641 ptc, 2 – 5 895 ptc, 3 – 10 184 ptc, 4 – 6 082 ptc, 5 – 6 350 ptc, 6 – 14 490 ptc.
Job 384 – particles from Job 380 class 2, total 58 104 ptc; ran successfully, final assignments per class: 0 - 8 969 ptc, 1 – 6 854 ptc, 2 – 5 488 ptc, 3 – 6 151 ptc, 4 – 10 363 ptc, 5 – 6 771 ptc, 6 – 13 781 ptc.
Job 385 – particles from Job 380 class 3, total 114 715 ptc; crashed during iteration 4 with error saying that 92 particles are with NaN; total used particles 10 184, assignments per class: 0 – 1 987 ptc, 1 – 369 ptc, 2 – 1 030 ptc, 3 – 4 327 ptc, 4 – 979 ptc, 5 – 815 ptc, 6 – 677 ptc.
Job 386 – particles from Job 380 class 4, total 63 265 ptc; crashed during iteration 1 with error saying that 500 particles are with NaN; total used particles 21 000, assignments per class: 0 – 4 445 ptc, 1 – 1 444 ptc, 2 – 2 200 ptc, 3 – 2 246 ptc, 4 – 2 257 ptc, 5 – 5 700 ptc, 6 – 2 708 ptc.
Job 387 – particles from Job 380 class 5, total 75 560 ptc; crashed during iteration 10 with error saying that 500 particles are with NaN; total used particles 21 000, assignments per class: 0 – 4 277 ptc, 1 – 1 032 ptc, 2 – 916 ptc, 3 – 1 034 ptc, 4 – 934 ptc, 5 – 995 ptc, 6 – 11 812 ptc.
Job 388 – particles from Job 380 class 0, total 51 850 ptc; ran successfully, final assignments per class: 0 – 6 222 ptc, 1 – 5 434 ptc, 2 – 9 503 ptc, 3 – 5 551 ptc, 4 – 5 210 ptc, 5 – 5 783 ptc, 6 – 14 147 ptc.
Just out of curiosity, I extracted particles assigned to the good volumes from the Hetero refinements that ran successfully (Job 381, 384, 388) and from the good Ab initio class (Job 380 class 3), box size 400 px with no Fourier crop. This way I got 156 120 ptcs and ran Non-uniform refinement with them successfully. Hoping that now the problem is solved, I wanted to further purify these particles by Hetero refinement (Job 395, the same settings as stated above). However, this job crashed again during iteration 4 with error saying 500 particles are with NaN. Total used particles 21 000, assignments per class: 0 – 8 688 ptc, 1 – 2 722 ptc, 2 – 1 381 ptc, 3 – 1 987 ptc, 4 – 1 959 ptc, 5 – 1 918 ptc, 6 – 2 345 ptc.
Please let me know should you need more information.
Cheers,
A.