Hi, I am processing some data taken with a K3 camera, and the majority of the micrographs are failing on the blob picker job with the following error:
File "cryosparc_worker/cryosparc_compute/run.py", line 84, in cryosparc_compute.run.main
File "cryosparc_master/cryosparc_compute/jobs/template_picker_gpu/run.pu", line 61, in cryosparc_compute.jobs.template_picker_gpu.run.run
File "cryosparc_master/cryosparc_compute/jobs/template_picker_gpu/run.py", line 249, in cryosparc_compute.jobs.template_picker_gpu.run.do_pick
File "cryosparc_master/cryosparc_compute/jobs/template_picker_gpu/run.py", line 376, in cryosparc_compute.jobs.template_picker_gpu.run.do_pick
File "/app/cryosparc_worker/cryosparc_compute/skcuda_internal/fft.py", line 134, in __init__ onembed, ostride, odist, self.fft_type, self.batch)
File "/app/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py", line 749, in cufftMakePlanMany cufftCheckStatus(status)
File "/app/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py", line 124, in cufftCheckStatus raise e
cryosparc_compute.skcuda_internal.cufft.cufftAllocFailed
I am using cryosparc v3.2.0+210817, micrographs from a K3 camera, and Geforce 2080Ti gpus. Interestingly, the blob picker job has run successfully on ~3000 of the micrographs, but has failed on all the others (~10,000). I have tried splitting these into smaller and smaller sets to find a corrupt file, even tried running on single micrographs, with no success.
Your GPU appears to have run out of memory. This may happen due to large values of certain input parameters (what was the extraction box size?) or due to another job that was also running on the same GPU. Were there non-CryoSPARC GPU tasks running at the time the error occurred?
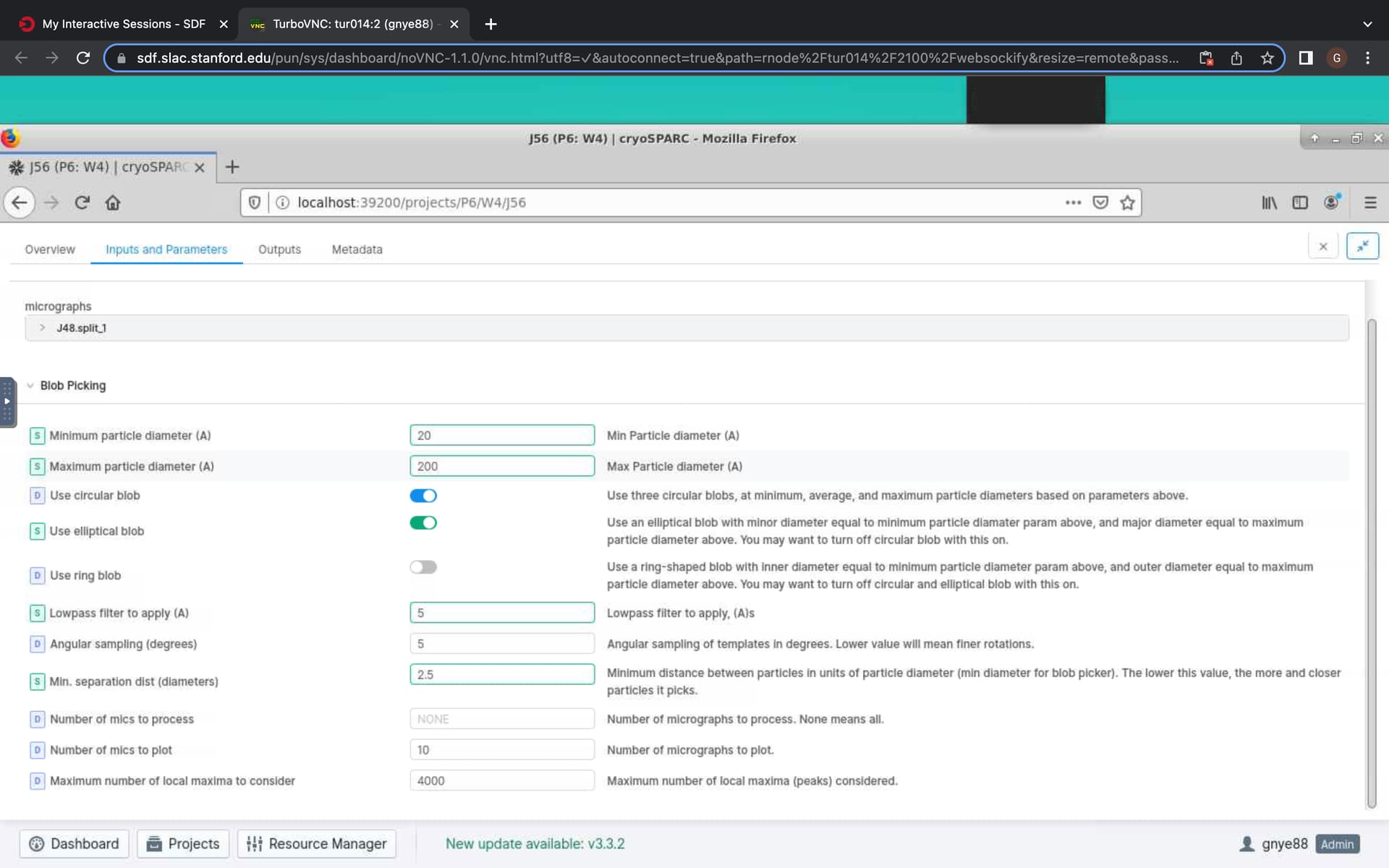
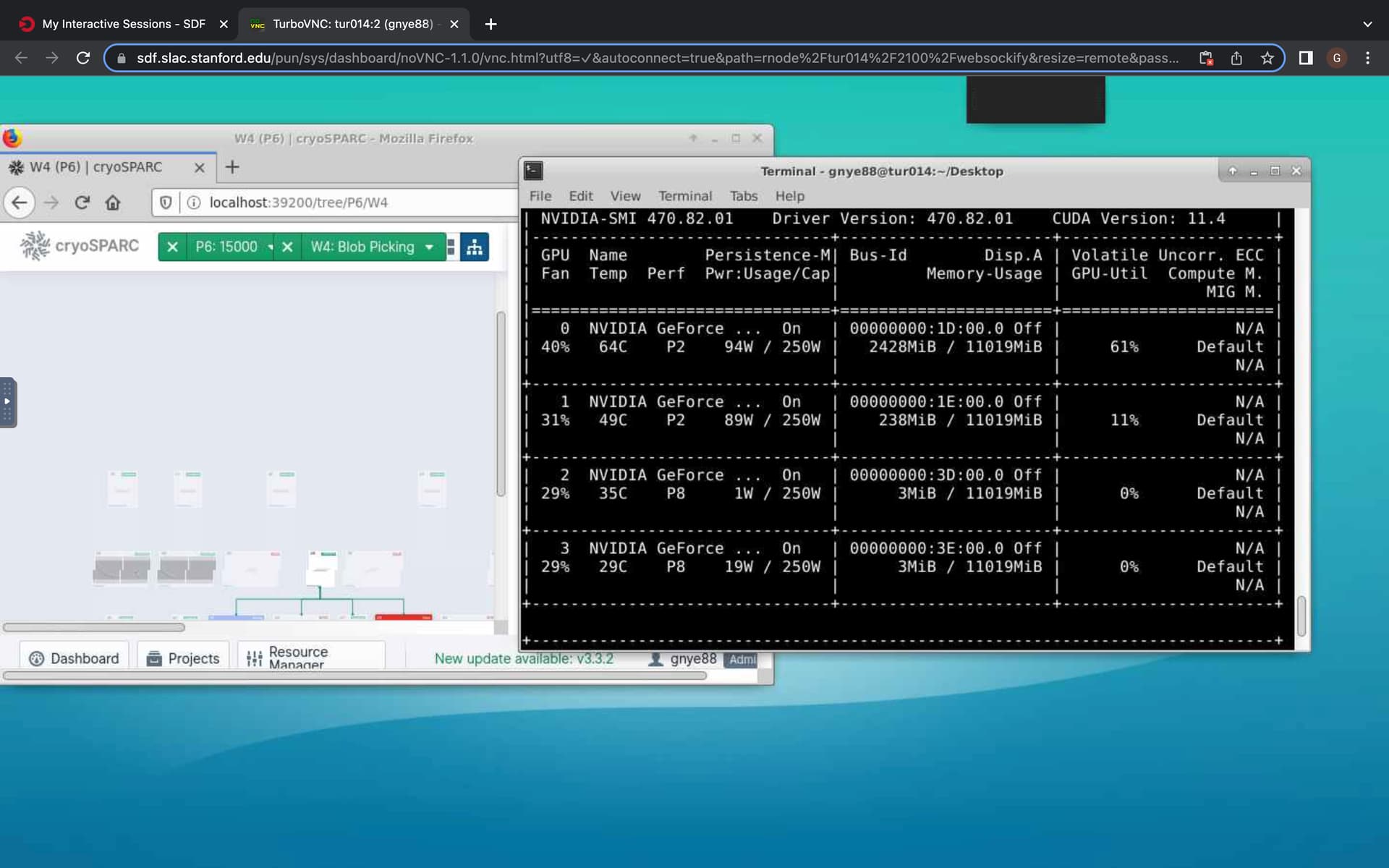
Hmmm the gpus had not run out of memory and there was no extraction box size assigned yet (blob picker job), but there were non-gpu tasks running at the same time - does this affect the gpu tasks? here is a picture with job parameters
The screenshot shows workloads for GPUs 0 and 1.
It is important that resources are allocated in consideration of all workloads.
If there are multiple CryoSPARC instances or additional, non-CryoSPARC GPU applications running on the computer, special precautions are needed to avoid “clashes” between GPU workloads.
Okay, thanks… This is my only CryoSPARC instance, and the only GPU application running was CryoSPARC. I tried assigning the blob picker jobs to GPUs 2 and 3 since I had other cryosparc jobs running on 0 and 1, which is why they are shown to have workloads. I have tried to continue with this data set and have been having the same error appear when I use template picker, even when I clear all other jobs and all GPUs have all memory available and no other jobs running at all. However, I have tried running some other jobs to test if all are failing (ab initio and 2D classification) and both of these were able to run successfully. Do you recommend anything in particular I can try to trouble shoot this issue because I cannot complete these jobs?
Dimensions of the movie files are 40 frames, 5760x4092
Blob picker was not able to succeed no matter how small the set of micrographs. I tried running on singles to determine if one micrograph was corrupted, but every one I tried failed. However, when I logged back on later, the same subsets of micrographs that failed were able to run.
It is most likely a GPU error, although it seems stochastic in timing. I am working on determining if there is anything on my end I can do to ensure that the GPUs do not have other workloads that I am unaware of.
Also interesting to note - I tried running blob picker on previous datasets I have finished processing, and those jobs failed as well (even though they succeeded when I first processed them). However, as stated, ab initio, heterogeneous refinement, 2D classification, and all other jobs seem to be running fine (with the exception of template picker), so it seems to be specific to picker jobs