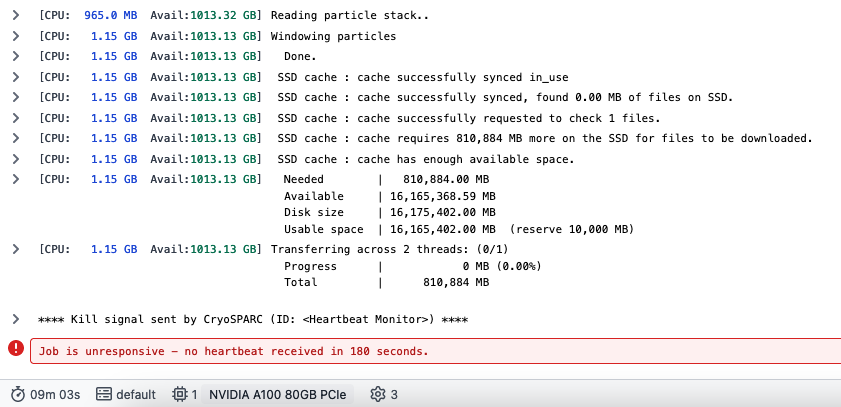
I tried running a 3DVA job on a particle stack containing 810k particles with a 512 box, but the job always gets stuck when caching all the particles to the SSD (screenshot attached). My particle stack is ~800GB and the SSD has a free space of 16TB, so there should be more than enough space to cache all the particles. I can run the job with “cache particles to SSD” disabled, but in that case each iteration takes more than 12 hours to run and is thus impractical. I was wondering if anyone has encountered this before and if there’s a way to work around it.
I’m using cryosparc v4.4.1. The particle stack was exported from Relion4.0. I’ve ran other 3DVA jobs on smaller particle stacks (300-400GB) generated in the same way and those jobs completed with no problems.
Welcome to the forum @csparc_addict.
What type of filesystem is used on your cache device?
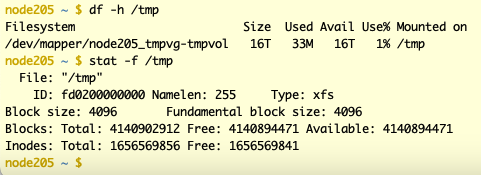
What are the outputs of these commands on the worker node after replacing /abs/cache_path with the actual path to the cache directory?
Hi @wtempel, thank you for your reply. Below are the outputs of those commands:
I’d like to add that I only have this issue when running the job on an a100 node. Yesterday I tried running the same job on an l40 node with a free SSD space of 3TB, and the job completed successfully.
The Structura team is considering several potential causes. Under one possible scenario, switching to the new caching implementation may help. This can be done by adding
export CRYOSPARC_IMPROVED_SSD_CACHE=true
to the cryosparc_worker/config.sh file of each cryosparc_worker/ installation used by your CryoSPARC instance.
Does this help?
Thank you for the suggestions. For the time being we are just running cryosparc on the l40 nodes simply because we haven’t had any issue with it. I’ll try the new caching implementation with the a100 node when I get a chance and get back to you later.
Please keep in mind that the switch to the new cache system should be made for all workers of the CryoSPARC instance. “Mixing”, where some workers use the old cache system, some other workers use the new, will likely break CryoSPARC function.