Question on the solvent mask in 3D classification - what happens if the focus mask includes regions that are outside the solvent mask? Is it OK to set the solvent mask threshold to 0?
Hey @DanielAsarnow,
We assume that the focus mask is strictly within the solvent mask, so those regions will be clipped off for the purposes of classification. During the E step of classification, we set each class volume to:
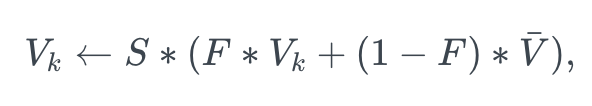
where S is the solvent mask, F is the focus mask, and \bar{V} is the consensus volume. If the focus mask is not provided, we set F = 1, and use S * V_k.
(See: Tutorial: 3D Classification (BETA) - CryoSPARC Guide for more info).
Valentin
5 Likes
The S*(FV+(1-F)V0) approach is a really cool cheap alternative to subtraction! I made the mistake though of only giving a “focus mask” input at first, which will probably be partly outside the automatic solvent mask. I wonder if a warning should be emitted if only a focused mask is supplied?
If only one mask is given it seems that it should always be input as the “solvent” mask; that’s equivalent to the behavior in the other imaging processing suites.
3 Likes
@vperetroukhin just trying to understand if I am understanding this correctly:
- The focus-masked region (F*V_k) is added to a volume where the focused region is zeroed out and density outside the focus mask mask from the consensus reconstruction is included ((1-F)*barV))
- This is then multiplied by the solvent mask to give the class volume.
Is this right? What is the effect of replacing the voxels outside the focus mask with those from the consensus reconstruction, rather than just masking them out? I.e. why use both, and not just a single mask covering the region of interest? Apologies, I think I am being dim…
And if this masking approach is beneficial for 3D classification, could/should it also be applied to 3D-VA or local refinement?
2 Likes
Hey @olibclarke,
- The focus-masked region (F*V_k) is added to a volume where the focused region is zeroed out and density outside the focus mask mask from the consensus reconstruction is included ((1-F)*barV))
- This is then multiplied by the solvent mask to give the class volume.
Yep, this is correct!
What is the effect of replacing the voxels outside the focus mask with those from the consensus reconstruction, rather than just masking them out?
As @DanielAsarnow mentioned above, the effect is similar to particle/signal subtraction done ‘on the fly’ (with fixed poses). This is better than the single-mask approach because it accounts for the way in which the (1-F) region ‘bleeds into’ the (F) region due to occlusions, or the CTF.
More specifically, if you work through the residual math for this new mask formulation, you get two relevant terms, one of which is identical to the ‘single mask case’ (i.e., |I - PFV_k| where P contains the pose/shift/CTF) and one which is an inner product between PFV_k and P(1-F)barV. This latter term can change the class distribution.
And if this masking approach is beneficial for 3D classification, could/should it also be applied to 3D-VA?
3D-VA already accounts for this in its formulation since the components can only change the consensus density within the supplied mask, so we effectively have the same F*V_k + (1-F)*V_0 structure.
Hope that’s clear!
2 Likes
Gotcha yes that makes sense now. So in that case, one would prob want the solvent mask to be very generous - covering the entire region (outside the focus mask) that might have some ordered density?
It seems if just a focus mask is provided, a solvent mask is automatically created which is a dilated version of the focus mask - I guess this is not optimal, if we want to take advantage of the “signal subtraction” like behavior?
Gotcha yes that makes sense now. So in that case, one would prob want the solvent mask to be very generous - covering the entire region (outside the focus mask) that might have some ordered density?
Yes definitely.
It seems if just a focus mask is provided, a solvent mask is automatically created which is a dilated version of the focus mask - I guess this is not optimal, if we want to take advantage of the “signal subtraction” like behavior?
Ah, great catch. The generated solvent mask is actually created from a dilated average of the initial densities, but these densities currently have a focus mask applied if it is supplied. This should not be the case so we’ll fix this! The auto solvent mask should probably come from the consensus volume (the averaging is a relic from v3.3 when we did not explicitly compute a consensus).
For now, using a solvent mask from a homo/NU refinement (or manually created one) would definitely be the optimal thing to do.
2 Likes
@olibclarke Going back to Figure 4 of Sjors’ book chapter “Processing of structurally heterogeneous cryo-EM data in Relion” with subtraction we end up comparing projections of the focused region to the subtracted images, which is “consistent” in that both of them have the same expected content.
With this F*V + (1-F)V0 approach, we compare projections of a constructed volume, which has the consensus structure outside the ROI and a unique per-class structure within the ROI, to the unmodified experimental images.
In the second case, the comparison is also “consistent” in Sjors’ terminology, however we can expect that the cross-correlation landscape will be compressed / lose dynamic range compared to subtraction, because of the matching in the consensus region. That is, the proportional density differences between classes are smaller, because the rest of the structure is also present. On the other hand it’s much cheaper than subtraction…
I would add that this approach might be really helpful for 3D classification with local search, with all that extra mass to keep alignments reasonable.
Edit: On second thought I have doubts about the last point. Hopefully we’ll be able to find out eventually.
3 Likes
That is a very helpful explanation, thanks Dan!
Would it also help to apply a lowpass filter of some kind to the consensus structure region outside the focus mask? Presumably the comparison will be more consistent at lower spatial frequencies where there is less noise, or am I understanding wrong?
We actually did think about this when we implemented the focus/solvent masks in v4 but opted to instead filter the entire S*(F*V_k + (1-F)*barV) structure according to its FSC.
1 Like
Ah right, yes that makes sense!
Returning here to note that v4.1.2 should fix this – the solvent mask is now generated (if not provided) from a dilated version of the consensus volume.
2 Likes