I have tried repeating the upstream jobs (Manual picker, 2D Class, Select 2D, Template picker, Inspect picks, Extract mic.) but I always run into this error at this step.
I am able to successfully run 2D classification on particles from Manual picker and Blob picker jobs using the same input processed micrographs (from Import movies > Patch motion > Patch CTF > Curate exposures jobs), so it seems to be a problem with Template picker particles specifically.
I am using v2.12.4
Has anyone else encountered this error, or has ideas for how I can troubleshoot this?
Thanks for reporting this. The error indicates that the number of particles in the actual .mrc particle stack file on disk are not the same as cryoSPARC expects given the metadata files (.cs files).
Usually something like this happens when people try to import particles from another program and have given the wrong pair of .star and .mrc files, but that is obviously not the case here.
Can you check to see if the number of particles reportedly outputted by the template picker job matches the number reportedly read in by the 2D class job? (in the streamlog of the 2D class, before the error, you should see a line that says Loading a ParticleStack with XXX items)
The Template picker outputted 432,272 particles. I then did an Inspect picks job outputting 423,625 particles. The Extract Job outputted 394,745, which is exactly what the 2D class job streamlog says.
I looked more closely at the Extract job and found:
So it looks like it did not extract all of the particles from the Inspect Picks job. Could this be the source of the issue? I looked at previous Extract jobs and they all had a similar stream log (outputted fewer particles than in the Inspect Picks job).
When you were seeing this issue, was it the case that you imported data (micrographs or movies) from two different directories? E.g. with a single import job that had a /*/*.mrc or /*/*.tif import, or using two different import jobs for different directories the outputs of which were then combined for picking and extraction?
We’ve found an issue that caused the ValueError that happens in this case, if there are two micrographs with the same filename in the two folders that were imported.
Please let us know.
Thanks!
I just got this same ValueError with cryoSPARC 2.14.2. My situation is like you describe: I imported particles already extracted by a different program (in this case, by Warp). Warp’s output consist of a bunch of mrcs files containing extracted particles (one mrcs file for each initial micrograph, if I understand correctly what it did) along with two star files: one for all particles, and one for “good” particles according to Warp’s particle picker. I imported the “good” particles only, which means there are more particles in the mrcs files than listed in the star file (and subsequent cs files in cryoSPARC).
The reason I am puzzled is that I had to import three sets of particles (i.e. three star files and the mrcs files they point to, each set in its own directory so I don’t think relative paths in the star files could point to an incorrect mrcs file), I did it the same way for all of them, and only one out of three gave me this error. I could successfully run class2D and subsequent 3D reconstruction and refinement jobs from two of these three sets of imported particles.
For the failed class2D job, I checked that it reports the same number of particles as the import job and that is indeed the case.
Yes, the error happens when I try to run class2D on this particular set. I have not tried to run it on all three sets at once (mostly because the other two sets could fit on my SSD cache while this last set is too big; so I was planning to run it over the weekend without caching).
I believe so (I have not checked each one), because they have the micrograph name as root name, and the micrographs come from EPU which wrote out each one with a timestamp in the file name (hence a unique name).
The mrcs files were copied twice: from the microscope to an external drive, then from this drive to the workstation I am using. I will double check that the copy didn’t mess anything up (the initial copy got interrupted, then resumed with rsync; it’s possible that this left one partially-transferred file because I always get confused with rsync’s options; I used -auP for this transfer, which may have caused such a problem).
So, to check whether reason 3 above could have caused a problem, I deleted the star file and all the mrcs files, and I made a fresh copy from the external drive. I imported the particles again (using the same import job that I cleared before repeating). I still get the same error at the beginning of class2D. Here it is in full:
[CPU: 2.53 GB] Traceback (most recent call last):
File "cryosparc2_worker/cryosparc2_compute/run.py", line 82, in cryosparc2_compute.run.main
File "cryosparc2_worker/cryosparc2_compute/jobs/class2D/run.py", line 155, in cryosparc2_compute.jobs.class2D.run.run_class_2D
File "cryosparc2_compute/particles.py", line 117, in get_prepared_fspace_data
return fourier.resample_fspace(fourier.fft(self.get_prepared_real_data()), self.dataset.N)
File "cryosparc2_compute/particles.py", line 112, in get_prepared_real_data
return (self.dataset.prepare_normalization_factor * self['blob/sign']) * (self.dataset.prepare_real_window * (self.get_original_real_data()))
File "cryosparc2_compute/particles.py", line 107, in get_original_real_data
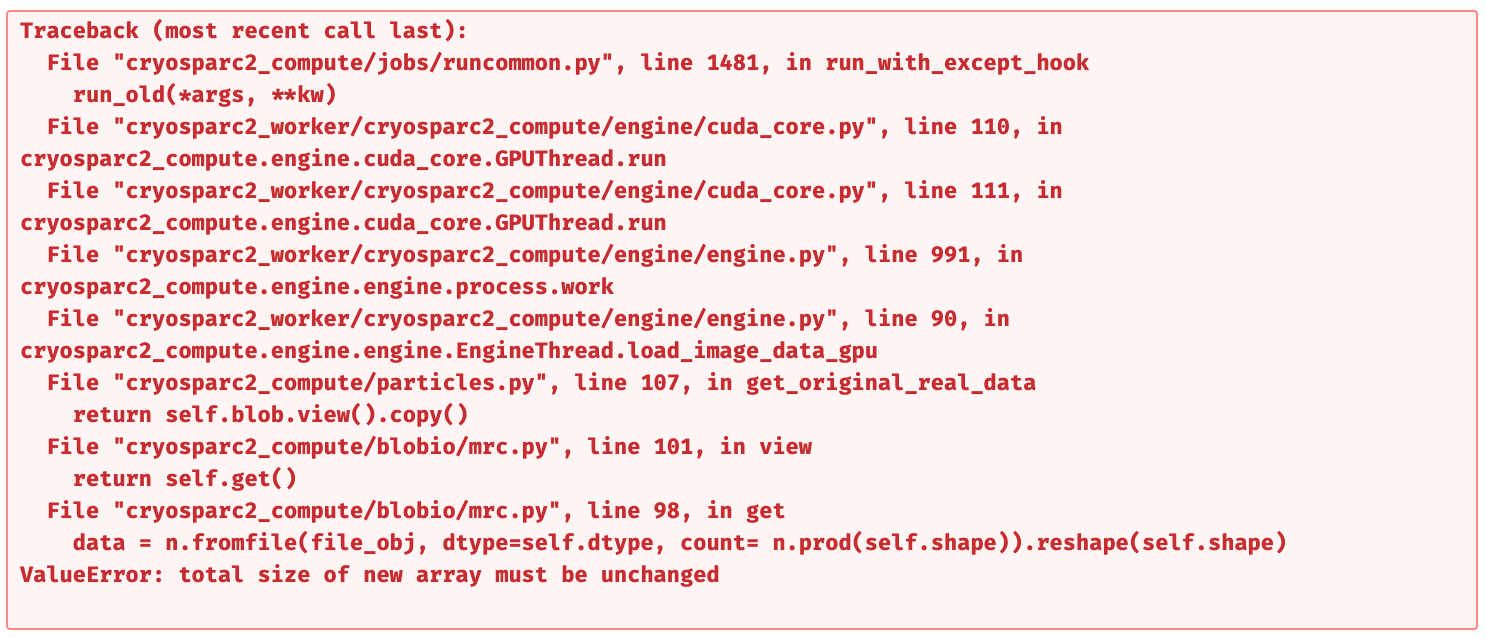
return self.blob.view().copy()
File "cryosparc2_compute/blobio/mrc.py", line 102, in view
return self.get()
File "cryosparc2_compute/blobio/mrc.py", line 99, in get
data = n.fromfile(file_obj, dtype=self.dtype, count= n.prod(self.shape)).reshape(self.shape)
ValueError: total size of new array must be unchanged
Is it possible if you can run this code for me, and email me the file it creates (sarulthasan@structura.bio)?
First, identify 3 variables, including the path to where the output of this script will be written to: project_uid : the uid of the project where the import particles job exists (e.g., P1) job_uid : the uid of the import particles job (e.g., J1) output_path : The path to the file where the stats will be written to (file will be created when the script is run)
Then, in a shell, run cryosparcm icli , which will open up an interactive python shell. You can then copy and paste this code, with the 3 variables modified:
import os
from cryosparc2_compute.blobio import mrc
project_uid = "P1"
job_uid = "J1"
output_path = '/u/cryosparcuser/header_stats.txt'
particles_dset = rc.load_output_group_direct(project_uid, job_uid, 'imported_particles')
proj_dir_abs = cli.get_project_dir_abs(project_uid)
for path in particles_dset.data['blob/path']:
filepath = os.path.join(proj_dir_abs, path)
with open(output_path, 'a') as file_out:
with open(filepath, 'rb') as file_obj:
header = mrc.read_mrc_header(file_obj)
file_out.write(filepath + ' : ')
file_out.write(str(header) + ', ')
total_file_size = float(os.path.getsize(filepath))
file_out.write("File size: {}, ".format(total_file_size))
file_out.write("Data Integrity: CORRUPT") if float(((header['nx']*header['ny']*header['nz']*4) + header['nsymbt'] + 1024)) != total_file_size else file_out.write("Data Integrity: Normal")
file_out.write('\n')
My class2D is running fine now, thank you for your help with this diagnostic script @stephan
For now I don’t really care about these 335 particles (out of ~2 million total), but when I’m done evaluating the dataset I will re-extract everything, so that might fix the problem too.