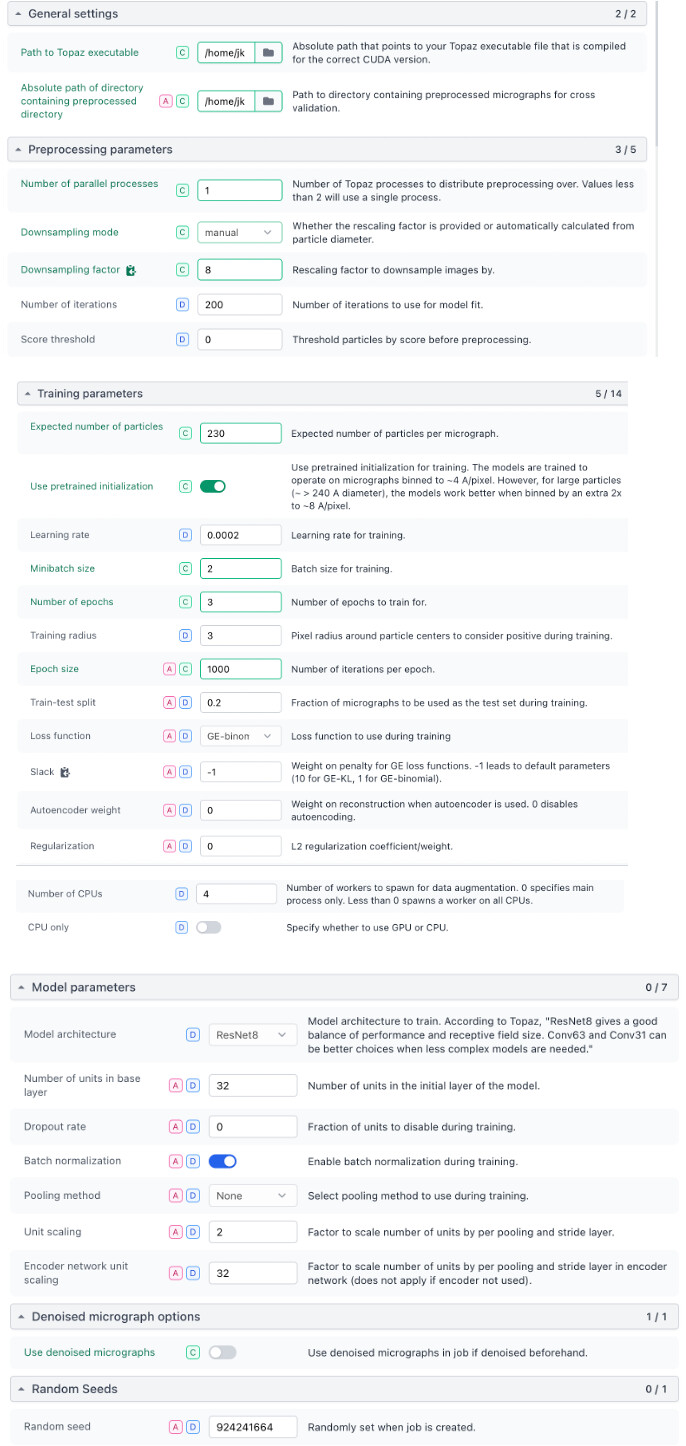
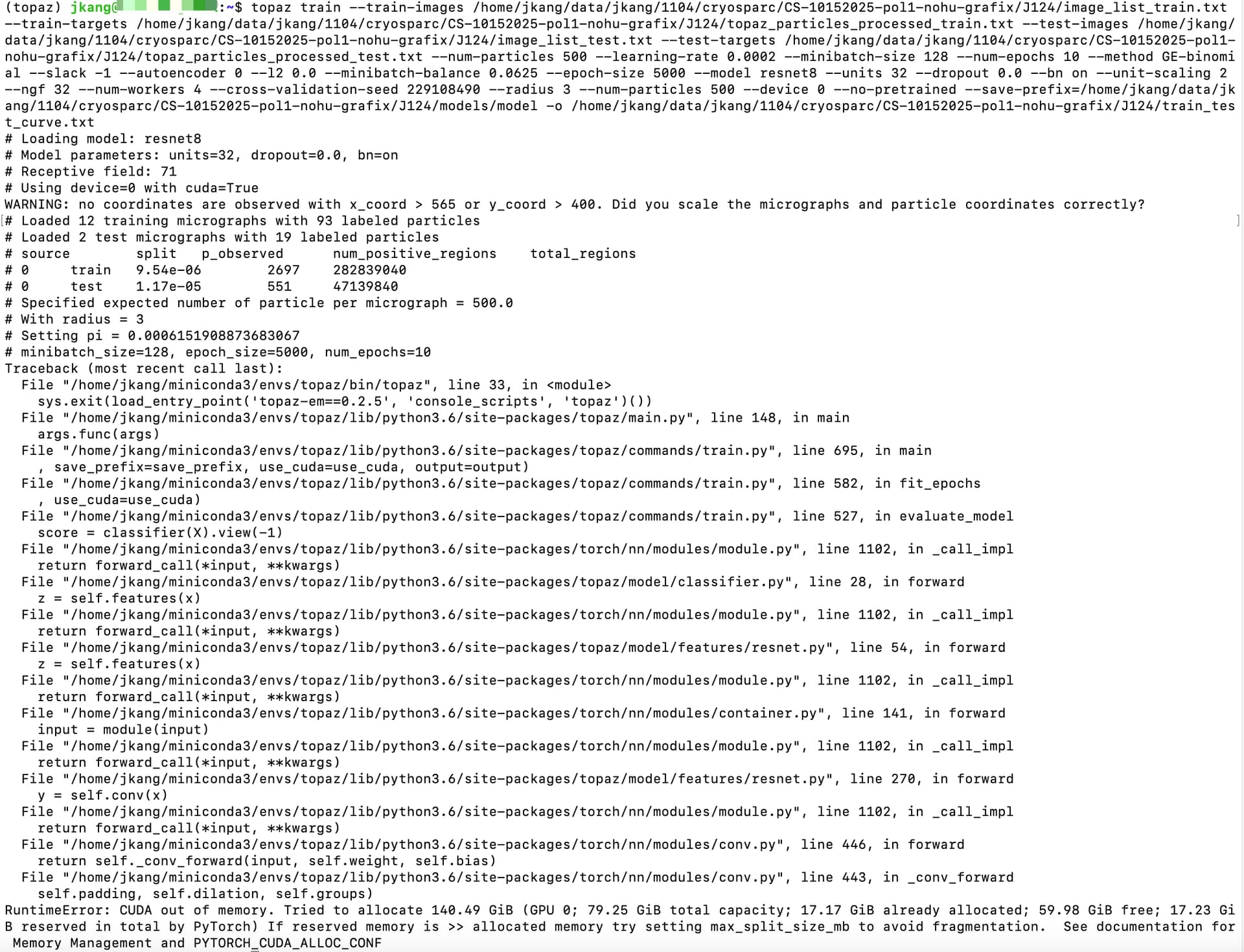
I installed Topaz following the tutorial. However, when I try to run a Topaz Train job in cryoSPARC, I encounter the following problem. I have attached the parameters I used and a screenshot of the error.
Given the small dataset (only 7 micrographs) and the very low training settings, the request for ~140 GB of GPU memory seems abnormal.
Is there a known issue in the Topaz wrapper or dataset tiling that could cause over-aggressive pre-allocation on the GPU?
Any suggestions or insights would be greatly appreciated.
This is definitely abnormal as 7 micrographs and particles for those micrographs shouldn’t be anywhere near 140 GB. Have you used Topaz before on other datasets or on another lane/node? Are you using SLURM?
Thank you for your reply.
I have not used Topaz before — this is my first time setting it up following the CryoSPARC tutorial.
I am running it on my own server, not using SLURM.
Based on this error’s presence when running from the command line, we would kindly direct you to the Topaz Github page for further support as we do not support failures with external software packages.