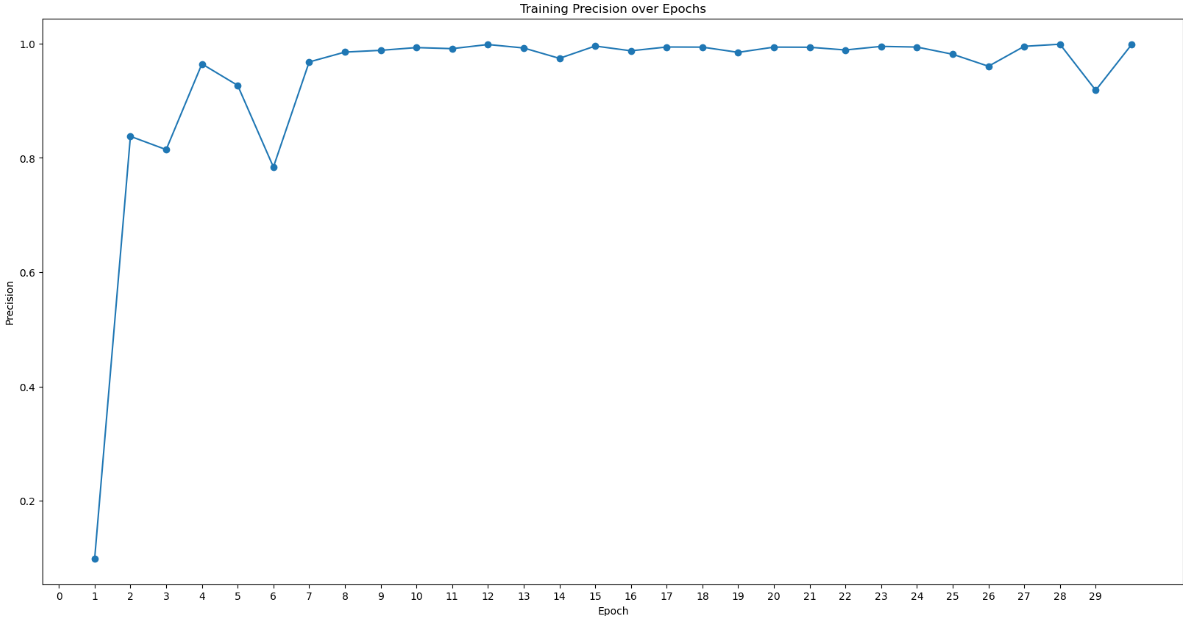
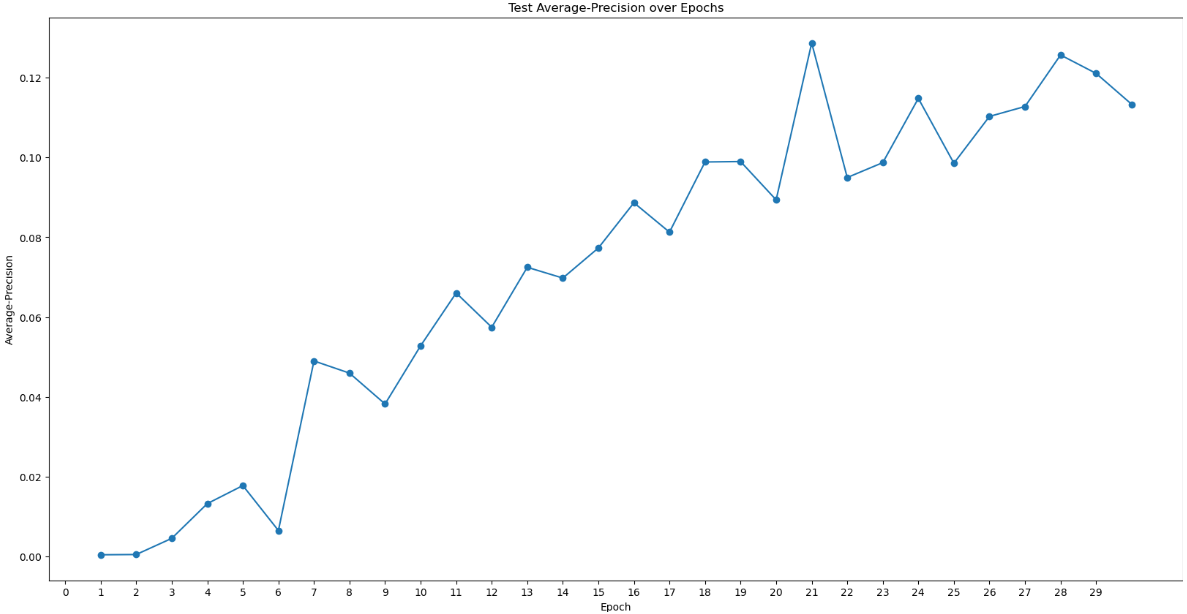
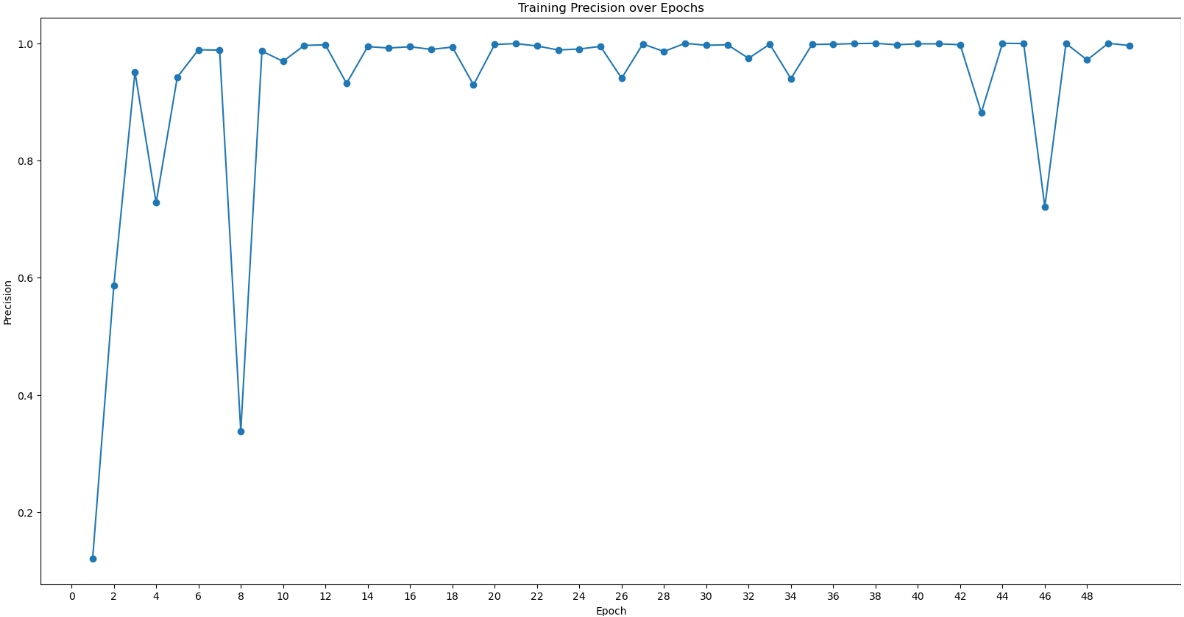
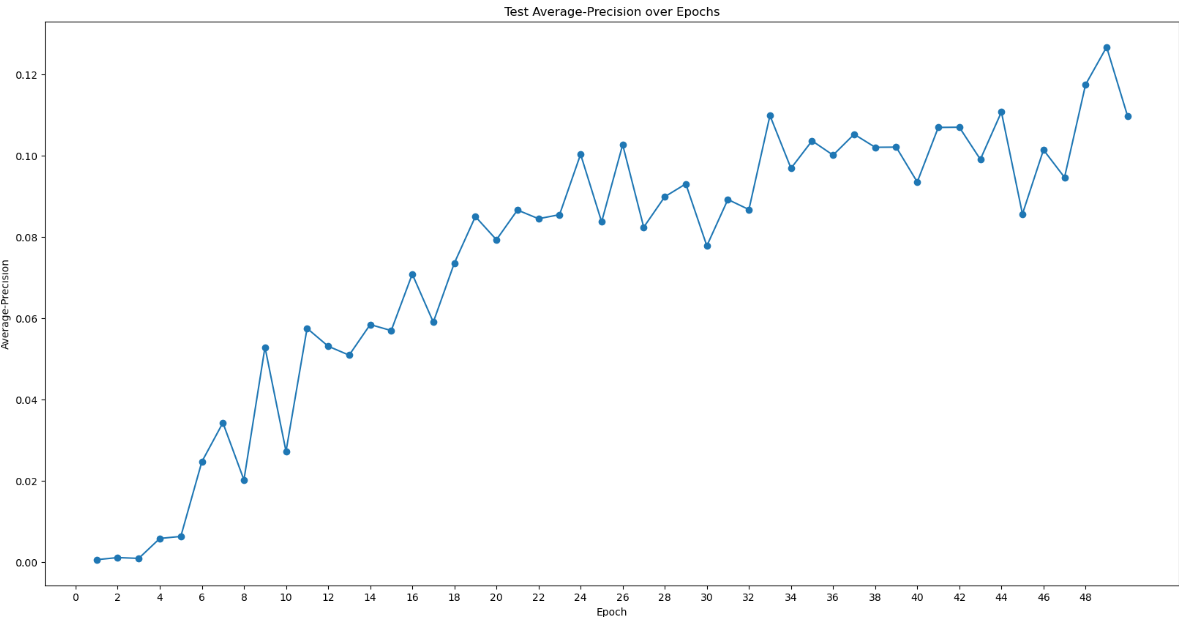
I used the 229 micrographs with 1023 particles to train the model.
The parameters: (the others are default.)
expected number of particles: 4
Number of epochs: 30
I thought that the training model was quite good. However, the test result had a very low value (near 0.1). In other cases, the value usually reached larger than 0.5. And I tested “50 epochs”.
Average-precision for the positive-unlabeled provides a relative number. Average-precision generally cannot be compared between different training parameters, and not compared to any absolute value.
Generally, it should gradually increase like your plots show. But in the end, models should be compared by how many good particles are picked and how many orientations are picked.
So, your plots look fine. But you should check the models by going through 2D/3D classification and 3D refinement.
I was trying the Topaz cross validation. I was very new about it. I selected the “expected number of particles” to optimise. And then, I got a better particle number parameter. The first thing I didn’t understand was the meaning of “Number of cross validation folds”. For example, the number of cross validation was 3. Then will it do 4 times Topaz train model to test the parameter “expected number of particles: 50, 100, 150, 200”? The second thing was that I didn’t find out the difference of the sub-jobs of Topaz train. I have seen there was a value in random seed. And the values in all sub-jobs were same. I wanted to know the difference of these jobs whose results were different.