Hello everyone. Recently, I used Topaz to pick particles, but I noticed that many particles were not picked after the Topaz training. To address this, I trained two separate Topaz models using two different sets of particles. After performing 2D and 3D classification on both particle stacks, each resulted in approximately 150,000 particles. After merging these two particle stacks, I obtained around 250,000 particles in total.
I am wondering why the two Topaz trainings produced such different results. Should I consider adjusting the parameters of the Topaz training to achieve more consistent particle selection?
I like to start on blob, get some really good 2D/3D e.g.
Manual pick~100 particles on denoised so I really see the max diameter, overall shape, how close particles are, and what would be a good extraction box size. So I could get for example Say ~150A and maybe 512 pix box.
Then Blob picker160A (usually ~10% bigger), picking within 0.3 diameters (lets say its concentrated), circle blob (pretend it looks like that), Inspect picks (no carbon or dark ice, NCC does not really matter here - high and low does).
Extract from micrographs (512pix Fourier crop to 64-128pix don’t need full box at this stage) maybe CPU only if others are using GPU, always 16 Floating points to save disk space. Good to know how many particles are extracted, is it 100k, 250k, 1m, 5m ? At this stage you really just need 50k-250k and if you collected 30k micrographs don’t really need to go through them all, 5k should be fine.
Start 2D classification - I like more classes but (128, 256 could be good - 384+ is too much), 40 EM iterations, some other stuff, select 2D to see any good ones.
I would put these good 2D into a multi-class Ab-initio (4-8 classes depending on particles). You can have it run as many particles as you want.
Ab-initio Reconstruction goes to heterogeneous refinement , inspect the 3D classes from Hetero (volume viewer) that look like something and run NU-refine or Homo refine.
From there ask how many particles are in the good class (how many per-micrograph?), is there any compositional heterogeneity, what is the cFAR, maybe run Orientation Diagnostics too.
If anisotropy is really bad, rebalance before anymore picking or the model will be biased.
This should produce really particles for TOPAZ training and you will benefit from the TOPAZ model, the way it centers and everything else.
Bonus, if a good 3D was reconstructed and you do another 2D Classification or just Generate Templates from it, you now have good templates for Template Picking.
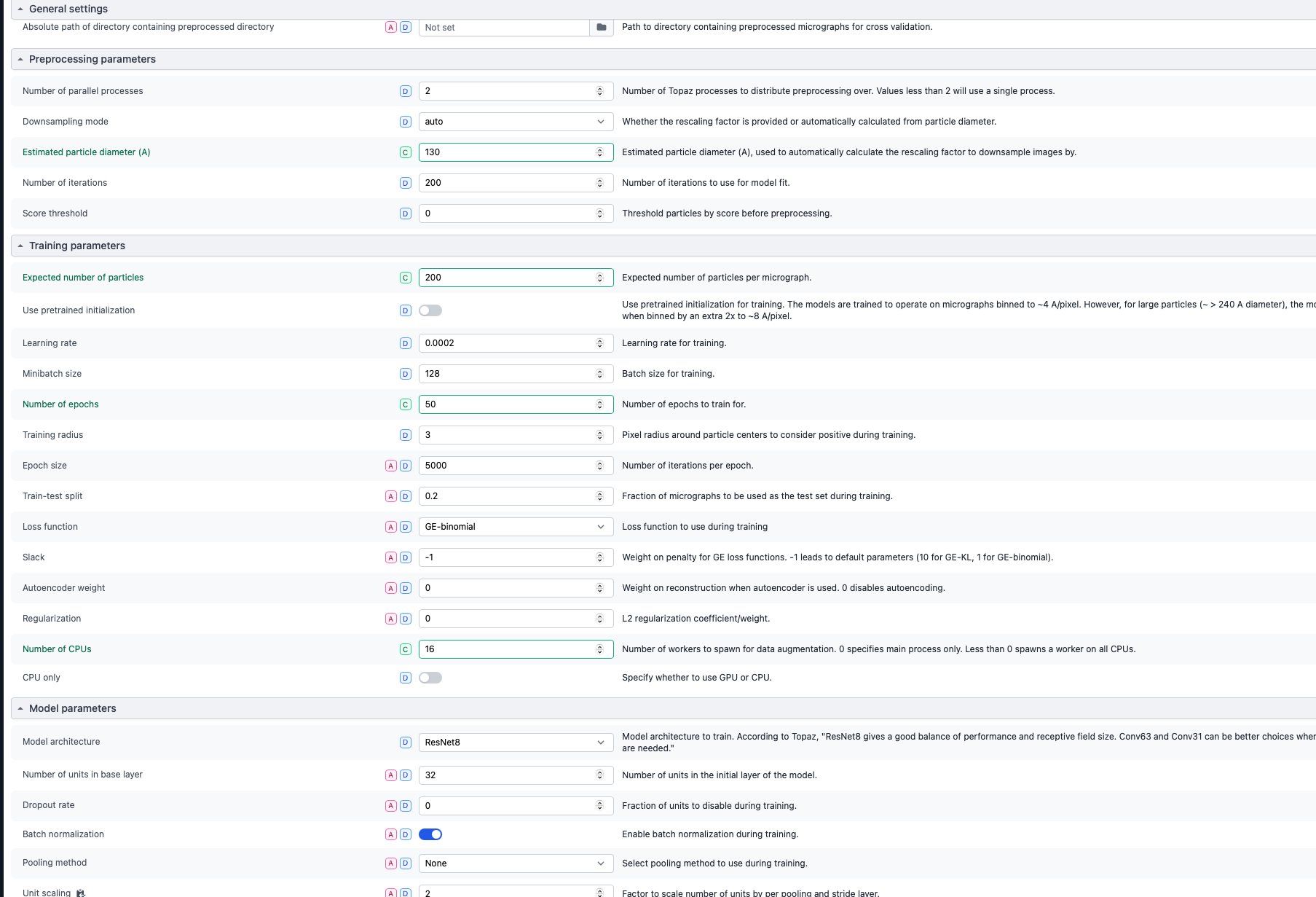
ensure 200 particles per micrograph is around what you expect, this is an important parameter for TOPAZ to be accurate.
16-32 Epochs is usually enough for the first go
The default CPUs is usually fine, make sure this actually works on your system or you have the resources.
ResNet8 is usually pretty good.
Also note, you have to carry these parameters over to TOPAZ extract and you may need to run your model in multiple TOPAZ extract jobs, as they only handle 5-7k micrographs without an error.
It is good to compare Blob, Template, and Topaz. *I’ve seen a lot of bad TOPAZ picking, just because it was not trained well - it needs accurate positive labels for training / accuracy.