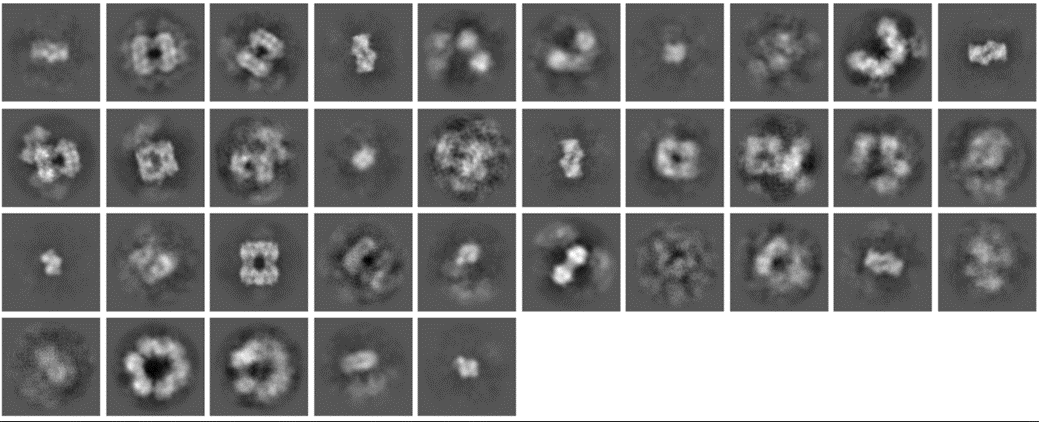
I am looking for some advice when working with a heterogenous sample. The sample is a mixture of oligomeric states, monomers (127 kDa) all the way to things that are approaching a filament (4mer X 8). I am most interested with this particular dataset in the larger structures, 4mer and up.
I have gone through blob picker to start off, and ended up getting some decent enough ab-initios to create templates for the various structures. I have since gone through template picker rounds and am getting a lot of picks of the “filaments”. Filament tracer doesn’t work likely since they are not really orientated in any given direction, and they are more like a mass of overlapping and touching “filaments”. I think that since they are abundant, template picker and 2d classification will be good enough for reconstruction later. I have only shown clear examples of the filaments but these are not representative of the majority of them.
The other structures are either being missed, or being picked on two/three different side (for ex. Green). This results in some unaligned picks, especially for the rarer views like the 12mer. It was suggested to me that I should try topaz and see if it can do a better job picking some of these rare structures. I started with manual picking of the 1mer, 2mer, 4mer, 8mer, and 12mers and purified with 2d classification (1500 particles).
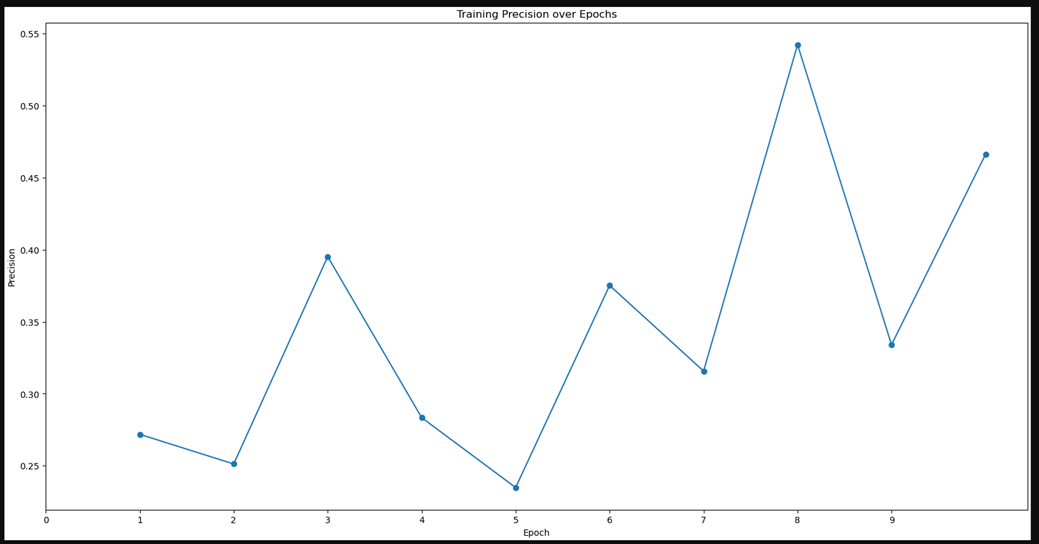
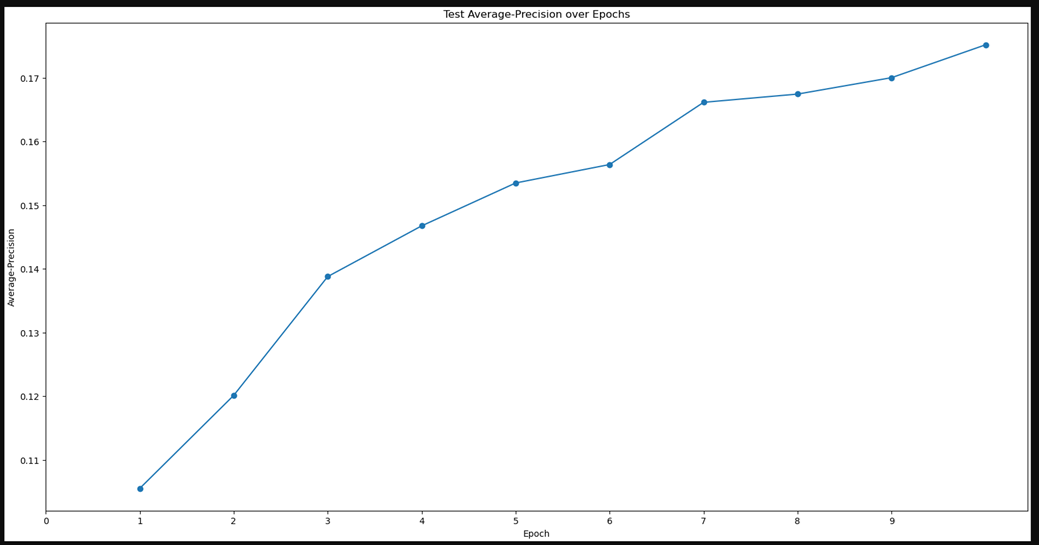
I combined this particle stack with the purified 2d classes of the filament. Topaz train ended up with this output (average precision ~ 0.18, training precision vs epochs flat at ~0.45) which suggests to me that it didn’t do a great job.
Is this because I am asking topaz to train on many different structures? Do I need to do a topaz training with each complex and then do downstream processing separately?
Second, it is worth removing sub-par 2d classes in favour of excellent one? I fear in this case with topaz training (and even 3d reconstruction) I am going to be throwing away views.
I’d definitely do multiple picking rounds with optimisations for each distinct structure - whether you later combine picks or keep them separate is a matter of personal taste. Monomer/dimer/tetramer can likely be picked together but the filament and octamer/dodecamer should probably be picked independently.
For Topaz, I’ve had superior results from obsessively cleaned data, but I will admit I don’t use Topaz all that often.
Will changing the max/min particle diameter in blob picker help ? You may have to get a lot of manual picks for each oligomer for proper training. Also if you have a model you can make some templates for each oligomer, again controlling for the maximum dimensions.
I would even go as far as saying I only trust a training set I have picked manually. This is because sometimes a small number of bad particles will not be detected in 2D class averages (not enough bad particles to group into their own class), but they will be enough to pollute your training.
I think the recommendation from the topaz developers has always been to manually pick ~1000 particles, and the practice of doing blob picker / class2D / select good ones for the training set has emerged mostly as a way to avoid the tedious manual picking, but at the expense of suboptimal training.
I have played around with this, however the dimensions that I am trying to capture are broad (100-500+ A) so there is a lot to pick (and miss!). I am trying to get a more targeted approach by selecting for rarer views and particles.
Thanks, seems like it might be best to train individual runs for each of the complex with particles picked. I still worry that, especially small stuff or things that are clumped, you will miss views by manual picking whereas blob/template is obviously less biased.
You can run the micrographs through topaz denoise before manual picking. In my experience it produces micrographs that are much easier to manually pick than simple low-pass filtering, and you can often find less obvious orientations more easily.
Also note that topaz learns to distinguish particles from background by “looking” at very few pixels. This message contains relevant info, the rest you can find in the help bubbles of the topaz GUI to figure out. In the “train” section, hover the mouse over the “Particle radius” blue parameter, and it will explain that the radius in pixels around the training coordinate defines what to consider as “particle” versus “background” further away from this radius. The default value of this parameter is very small: 3 pixels. So, if I understand this correctly, it shouldn’t matter too much that you miss certain views in manual picking, as long as they have a similar pixel value distributions as other views (sufficiently different compared to the background, I suppose). Again if I understand correctly, this is why the downsampling factor is one of the most important parameters, and presumably one could compensate for insufficient downsampling by increasing the particle radius (but in terms of computational efficiency, it is better to keep the radius small and downsample more to bring the particle size in the ballpark of this small radius: this will produce smaller micrographs, which will take less time to train and pick).