Hi all. For some reason, ever since we moved cryosparc from AWS to a supercomputer cluster, we have not been able to run TOPAZ. The error that I get when trying to run TOPAZ train is pasted below. I really have no idea how to solve this and would love any possible advice or assistance.
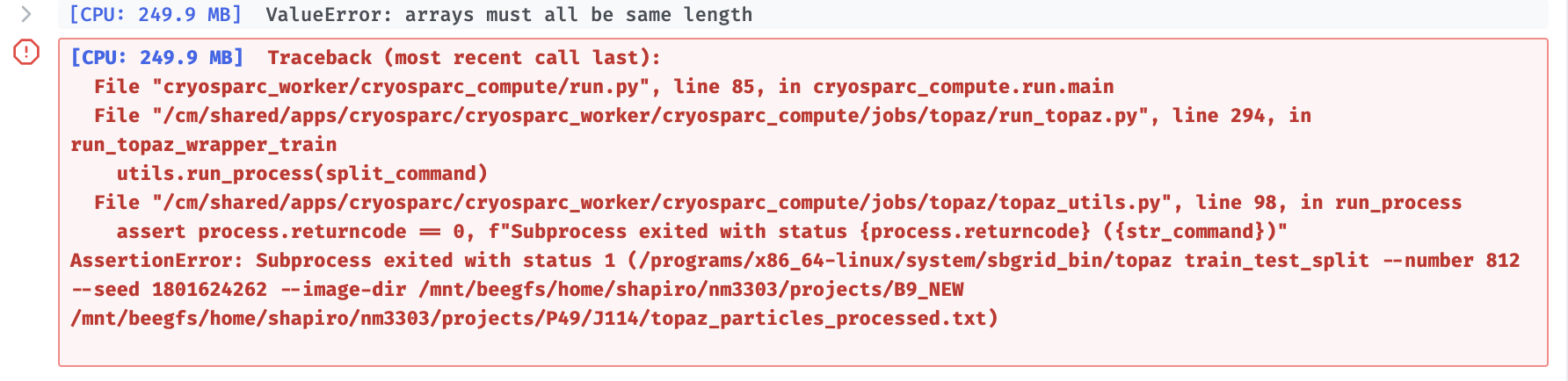
The job log (Metadata|Log) may contain more information.
For better control over the Topaz software environment, may I suggest:
- Install topaz in a fresh conda environment, as described in the using Anaconda section here. Ensure that the conda environment
- is created outside the CryoSPARC software directories
- accessible on the worker nodes
- Create and use a wrapper script