and I can’t kill it or delete it unless I restart cryosparc
ie.
cryosparcm stop
crysosparcm start
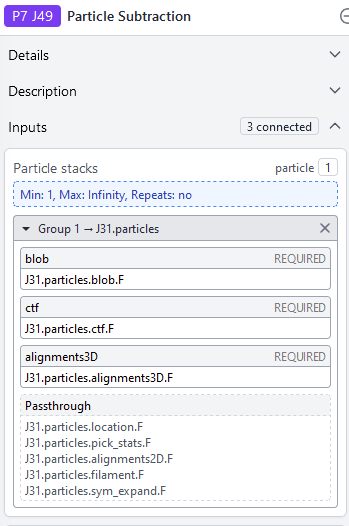
Not sure if this part of the problem but the input particles are from a symmetry expansion job. Running a particle subtraction job with the non-symmetry expanded particle dataset does seem to work.
I ran a test to check if the problem was due to using the asymmetric expanded particles as input, but this does not seem to be the problem. I re-stacked the particles and gave them as input to the signal subtraction job and the same problem arises:
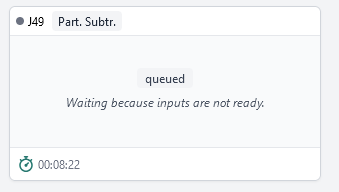
Job status:
queued
waiting for inputs
I also tried to use a reduced size symmetry expanded particles dataset as as input to test whether the problem was due to too many particles (~5 million). The reduced symmetry expanded set (order factor 2, approx 700000 particles output) as input to the the signal subtraction job resulted in the same problem:
Job status:
queued
waiting for inputs
As I said the job stays in this status longer than any other other job performed with the same dataset (at least overnight). and with no indication about what these ‘inputs’ that it is waiting for may be.
Has the signal subtraction job being tested with helical and helical symmetry expanded particles? Are there any examples?
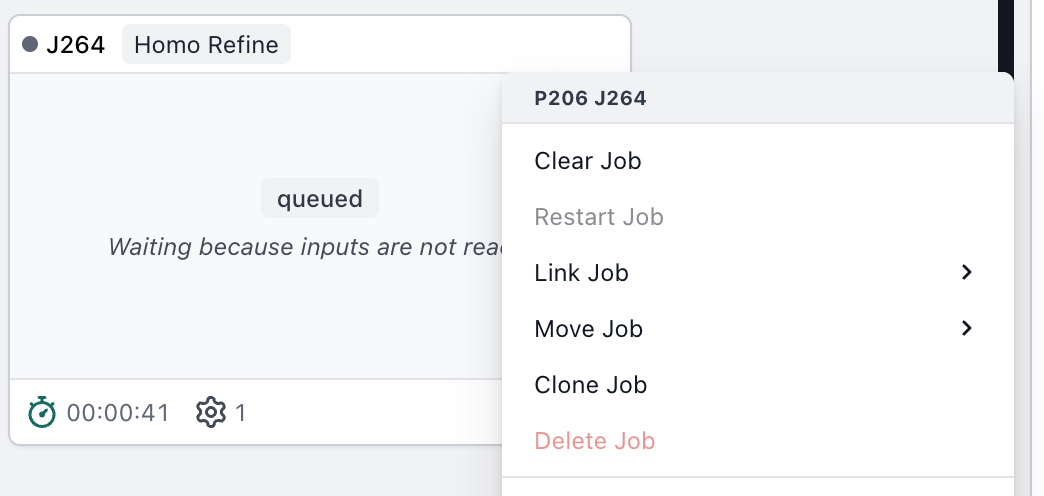
Thanks @hsosa for these details. It may not be possible to delete or kill a job in the waiting state. Please can you show the actions available in the menu of the job card for J49 when J49 is waiting for inputs, similar to this example:
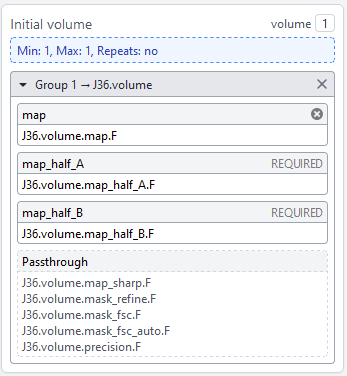
I realized that J36 a local refinement job failed to finish. It says;
Job is unresponsive - no heartbeat received in 180 seconds.
I guess I was using one of the intermediate volumes output of this unfinished job as an input to the signal subtraction job. So maybe this job was waiting for the failed job to finish ???
I don’t know, though why the local refinement job ended in failure. This job was also using the symmetry expanded particles as input.
@hsosa Our best guess is that the the worker computer on which the local refine job ran may have run out of system RAM and started swapping or stalled for some other reason.