I have a K3 dataset (TIFF files), which was not gain corrected during acquisition. The provided gain reference file is also in TIFF format. I understand that CryoSPARC requires the gain reference in MRC format. I have converted the TIFF file to MRC in Bsoft using the following command
“bimg -datatype b gain.tiff gain.mrc”
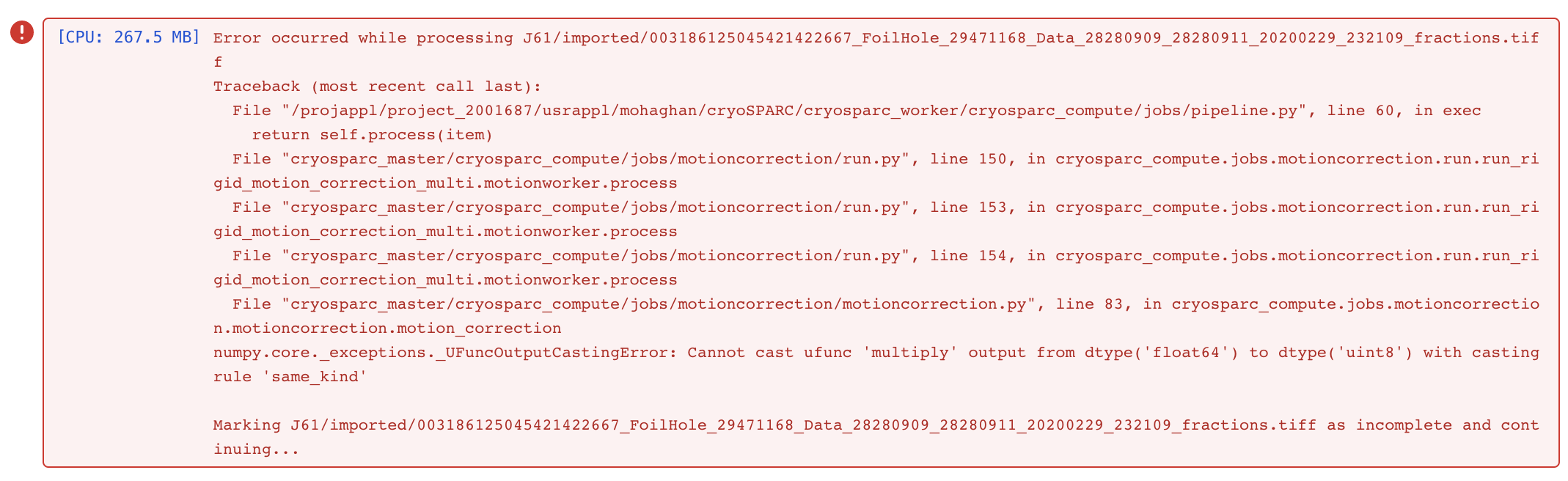
This produces an unsigned 8-bit MRC file. When I run “full frame motion correction” I get the following error:
numpy.core._exceptions._UFuncOutputCastingError: Cannot cast ufunc ‘multiply’ output from dtype(‘float64’) to dtype(‘uint8’) with casting rule ‘same_kind’
If I import the same movies omitting the gain reference file, the job runs fine.
Any suggestions how to convert the gain reference so that CryoSPARC can read it? CryoSPARC ver 4.1.1
Unless there’s a specific reason for using full-frame motion correction, I’d recommend trying with patch motion correction. That being said, this still looks like it could be a bug. Could you paste the full error message that you’re seeing? A screenshot of the stream log might be best.
With a K3, I’d generate a gain reference fresh from the data anyway. Use RELION or cisTEM to do so. I’ve often had to make multiple gain references across a dataset if it was collected over more than 12 or so hours, because the K3 can demonstrate pretty severe gain drift.
Using CDS mode, we see no significant gain drift on our K3. We also usually let GMS gain correct, as it has given better results than applying binned gain files from the GMS-reference directory or RELION/cisTEM derived gain files during some – admittedly not super-well controlled – tests. The disadvantage is, of course, slightly larger movies.
Thanks for posting the full error message. I’m not familiar with bsoft or the bimg command, but does -datatype b mean “byte” as in uint8? If so, that could be the problem. You could verify this by taking a look at the mrc file header, for example by running xxd -e -g 4 /path/to/gain-reference.mrc | head and taking a look at the first line it outputs. If the last batch of numbers is 00000000 then the file is in uint8 format.
In any event, this is a bug in the sense that CryoSPARC should certainly provide a more helpful error message when this happens, but if the gain reference is indeed uint8 then that’s definitely not going to work well in any event. Try re-running your bimg command and choosing float32 as your output datatype.
This error lead me earlier to think that cryoSPARC expects the gain reference as uint8 MRC. Do you have a suggestion how to convert the TIFF format K3 gain reference to a compatible MRC format? Thanks!
In the meanwhile I have also tried making a new gain reference by averaging 1500 movies in cisTEM (using the command “sum_all_tif_files”) as suggested by @rbs_sci. This gain reference is float32. When I try to import the movies with this gain reference, I get the same error as above when trying to import the float32 gain reference converted with Bsoft:
“numpy.core._exceptions._ArrayMemoryError: Unable to allocate 89.9 MiB for an array with shape (8184, 11520) and data type uint8”
I can import these movies fine, if I don’t provide any gain reference. Obviously this is not the solution, but it isolates the problem to the gain ref import. Many thanks for your help
Yes that xxd output looks like what I would expect to see for float32, but the error you’re getting now seems quite puzzling. What are the specifications of the machine you’re running cryoSPARC on? If you know them you can just list them, but otherwise you can run lscpu && free -g && uname -a && nvidia-smi, which will output details about the cpu, memory, linux version, and GPUs.
Another thought: is this a fresh install, or was it an upgrade from an earlier version? It also might be worth checking that your python and numpy versions got installed correctly… from the command line you can run /path/to/cryosparc_worker/bin/cryosparcw ipython which should print out the python version and start an interactive python prompt. Run import numpy; numpy.__version__ which should print the numpy version and then you can exit with control-d.
I may be misunderstanding, but I read this as you are converting the cisTEM output (float32) to uint8 with bsoft? Just use the float32 gain.mrc, I always have done and it works fine for me (either counting, CDS or super res mode)…
For mismatched Python versions, made sure conda is deactivated. That gets cryoSPARC really confused.
What I meant was that I get the same error with the float32 gain ref made in cisTEM (sum_all_tifs) and a float32 gain ref made in Bsoft (conversion from TIF to MRC). In both cases, the error is
“numpy.core._exceptions._ArrayMemoryError: Unable to allocate 89.9 MiB for an array with shape (8184, 11520) and data type uint8”
This issue with gain ref at import movies step is the only thing that fails with our installation, everything else seems ok. We are looking into the Python version mismatch.
Sorry, the information I gave above was for different installation than what gave the error. I have now checked the actual installation (the one giving the error). There python versions of both master and worker are 3.8.15. This was a fresh 4.0.1 install which was upgraded to 4.1.1.
You mentioned that this is on a cluster system? Since this data is K3 super-resolution, which is quite large, I’m thinking that the job is actually running out of memory. Not exhausting the compute node’s RAM, but reaching the limit imposed by SLURM.
It’s possible to adjust cryosparc to ask for more memory from SLURM, but it’s not super straightforward.The easiest way to do this is as follows:
Modify the file cryosparc_master/cryosparc_compute/jobs/imports/build.py, replacing line 251 with:
Yes, our installation is on a HPC system. Thanks for the instructions, but are these applicapable in the case of Import Movies job? (After fixing the gain reference datatype (to float32), the error occurs already at the Import Movies step.) As this step runs on the front node of the HPC cluster (not on a compute node via SLURM), and memory allocation for interactive jobs is limited on the front node, it is possible that it runs out of memory. If there was a way to send Import Movies job to a compute node via SLURM, then this might solve the problem.