To make SSD caching in CS possible, we have just installed NVMe drives in all our GPU nodes.
Holy moly! that gives some significant speedup in processing, especially if one has large particle stacks.
Thanks for that option!
But this brings back an old tropic that I have tried raise some times before.
For most cryoSPARCs jobs, their ability to pull data off our Cephfs disk cluster, is rather poor performing.
It would be nice if all jobs in CS, were given the opportunity to use “parallel disc I/O” like the option Relion has. I believe this would give another significant speedup of cryoSPARC, as bandwitdh of Relion easily is above 15 Gbps from our Cephfs, while cryosparc (except for import) only is around 1.5 Gbps.
I hope you will consider this in future version of CS?
Best regards,
Jesper
P.S. Although cryoSPARC has move to Python3, it still looks like shutil.copyfile only has a buffersize (length) of 16 KB, is this true? If so, I think an increase to e.g. 16MB would make a huge impact on bandwidth on network drives?
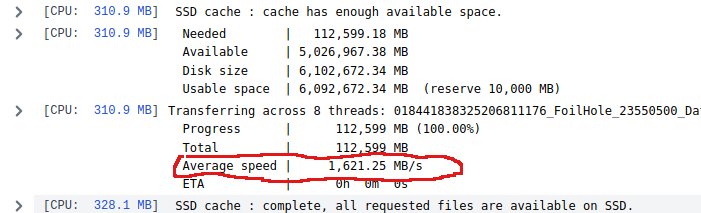
Great job with the v4.3.0 release.
Due to the “CRYOSPARC_CACHE_NUM_THREADS” config option, we can now transfer particle stacks from our Ceph disk cluster to SSD much faster than before.
Not for these either (and no future plan at the moment), I think the best alternative is to use multiple GPUs, which will spawn a process for each GPU, effectively doing “parallel IO”.
Okay sounds great with parallel transfers for non-SSD cached jobs. Looking forward to it and perhaps we can skip the expensive SSD cache disks entirely after that
The reason that I asked about parallel transfers for extract jobs was that, to free up resources on GPU-nodes, we mainly use the CPU-only part of “Extract from Micrographs”, which could become super fast if parallel transfer was enabled.
Especially if the CPU node has many CPU cores and high network bandwidth.
This would be great for us too! We often use the CPU version of extract micrographs so we can save GPUs for more important things, anything that can speed this up would be very helpful