Once I’ve got good per-particle scales in a dataset, should it need to be reset and re-run each refinement?
I’ve got a helical dataset (the one I will show is a TMV sanity check, not the real data) where I can hit physical Nyquist (<1.9 Å)… that’s not the issue. The issue is pre-Global CTF and Local CTF estimation, I had good per-particle scales, so I switched off reset/re-calculate… and the first iteration of helical refinement always crashes with a size zero error. Doesn’t matter whether I use the output particles from the previous refinement, the particles from Global CTF or the particles from Local CTF, the crash is the same.
As long as I either (a) reset the per-particle scale or (b) reset and re-calculate per-particle scaling, the helical refinement will succeed without issue (and the TMV sanity check also hits physical Nyquist, which is nice…) using 8K sampling from the EER data gives expected FSC.
Why does taking per-particle scales from a previous job and not resetting them cause this error?
Thanks in advance.
edit: Resetting but not re-calculating per-particle scaling results is a slight loss of reported resolution (not statistically significant) in the final reconstruction compared to both reset and re-calculate.
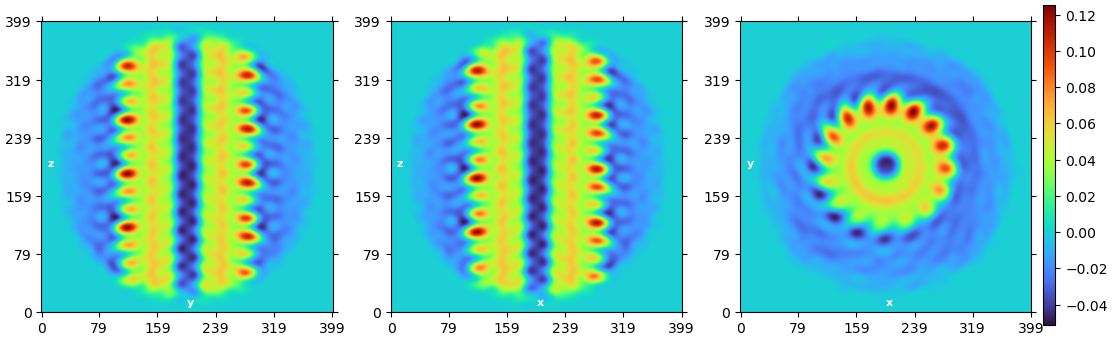
This is quite strange; I don’t think we’ve seen it before! Based on where the error is happening, could you post the plots from the 0th iteration of the failing job? Particularly the real space density plots of both the volume and the mask would be informative.
Could you also let us know what input was used for the mask, as well as which parameters were set to non-default values?
It’s immediately obvious that it’s gone nuts (even before the plots appear) because the first fit runs to almost-Nyquist (“Using filter radius…”) when on a “good” run it will fit to ~2.4A.
I’m allowing it to recalculate a mask on the fly (no static mask attached).
Custom parameters were:
Helical twist estimate (degrees): 22.034 (calculated from previous run)
Helical rise estimate (Angstrom): 1.384 (calculated from previous run)
Do symmetry alignment: OFF (using already aligned map)
Resolution to begin local searches of helical symmetry: 0 (disable symmetry searching)
Fix search grid: OFF (do not want)
Use non-uniform refinement: YES (want NU Refine)
Number of extra passes: 2
Reset input per-particle scale: OFF (previously calculated)
Jobs with identical settings except for the per-particle scale complete and give excellent results.
Thanks @rbs_sci for the information. Based on this, my suspicion is that there are invalid values (perhaps zeros or NaNs) in the per-particle scale from the upstream refinements. If you have CryoSPARC Tools installed, would you be able to verify this for me by running a simple script?
import numpy as n
from cryosparc.tools import CryoSPARC
cs = CryoSPARC(host="<hostname here>", base_port=40000)
assert cs.test_connection()
project_number = "PXXX" # project number here
job_number = "JYYY" # job number here (upstream of the helical refinement)
project = cs.find_project(project_number)
job = cs.find_job(project_number, job_number)
particles = job.load_output("particles") # you may need to modify the name of the output argument here
print(f"Min alpha: {n.amin(particles['alignments3D/alpha'])}")
print(f"Max alpha: {n.amax(particles['alignments3D/alpha'])}")
print(f"Any zeroes? {n.any(n.isclose(0.0, particles['alignments3D/alpha']))}")
print(f"Any NaNs? {n.any(n.isnan(particles['alignments3D/alpha']))}")
edit:
Output from failing job:
Min alpha: 0.0
Max alpha: 0.0
Any zeroes? True
Any NaNs? False
The identical job which has per-particle scaling reset reports:
Min alpha: 1.0
Max alpha: 1.0
Any zeroes? False
Any NaNs? False
The identical job which has per-particle scaling reset and recalculated reports:
Min alpha: 0.035231757909059525
Max alpha: 1.3187696933746338
Any zeroes? False
Any NaNs? False
A second job which has per-particle scaling reset and recalculated reports:
Min alpha: 0.036313191056251526
Max alpha: 1.322471261024475
Any zeroes? False
Any NaNs? False
And the originating job (where scales should be taken from) reports:
Min alpha: 0.05159826949238777
Max alpha: 1.310579538345337
Any zeroes? False
Any NaNs? False
Min alpha seems extreme? I don’t remember any of the micrographs looking particularly high or low intensity, but I’ll run through them again to check. Everything is 16-bit MRC. Can CryoSPARC/(tools) dump out say, the 1% of particles at each extreme for a sanity check?
Just to confirm, this is the job directly upstream of the helical refinement, from which the particles were connected?
This is quite suspicious. Since the job failed after iteration 0, there was at least one iteration complete, so I think this might be our issue. Somehow the scales are reset to zero by the job, and are not preserved from the upstream job. We’ll try to reproduce this.
Thanks for finding this. We’ve recreated this internally, it is indeed a bug particular to helical refinement, specfically in the case where “Re-estimate greyscale level of input reference” is False. We’ve noted a fix for a future release.
In the meantime, the most straightforward way to workaround this is to enable “Re-estimate greyscale level of input reference”. Note that this will keep the scales intact, and will apply a single multiplicative factor on the initial volume to match the greyscale range of the particles. This only affects iteration 0’s results (in future iterations, the reference is created directly from the particles, so naturally has the correct grayscale).