I imported 9 different optics groups as 9 separate “import movies” jobs. Then I combined them at the patch align step, and did everything together. Later on I tried to do “global ctf refine” to fix beamtilt. However it only plots output for group 0. and overall it has very little effect, despite using quite a big beamtilt during collection. I’m wondering if it isnt treating my 9 groups separately?
I think everything is in group 0 unless you assign groups using Exposure Group Utilities. Also, the exposure group IDs are global, not per-particle set. Thus, you almost always need the to use the group ID offset if you will combine different particle sets.
For example, I use a 3x3 image shift pattern in SerialEM and all the images end in _0001 … _0009. Splitting then creates IDs from 0 to 8. If I have two separate datasets, and I want 18 exposure groups in a combined refinement, then I need to split the second dataset with an offset of 9, to create IDs from 9 to 17. Otherwise it will also have group IDs from 0 to 8 and they will be mixed with the first set’s 0 to 8.
In your example, though it’s a bit tedious, you can use Exposure Group Utility to split each import into just 1 group and manually set the offset for each one…
thanks for getting back to me. I have only one dataset. I split them into optics groups in advance using X/Y shift from leginon and Kmeans clustering. I then imported each group as 9 different movies, all belonging to the same dataset. Is the excerpt below (from the tutorial) no longer valid? Should they not have been assigned an exposure group ID at time of import?
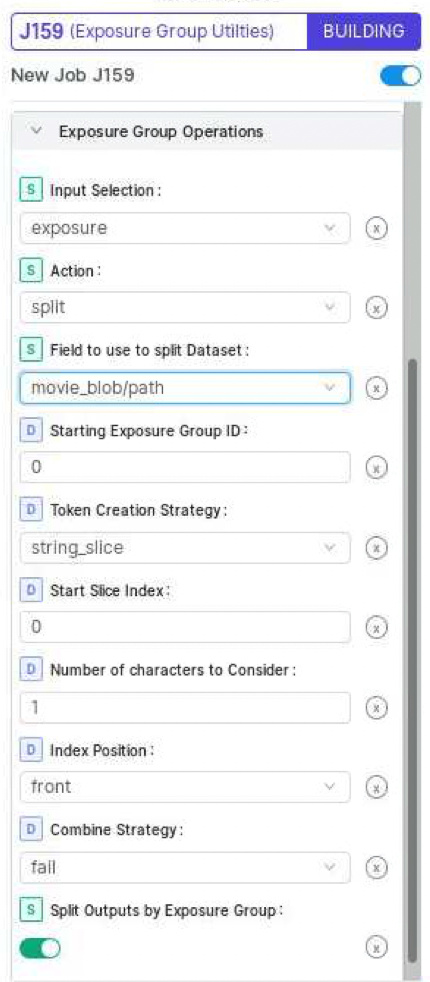
This is quite tedious indeed. When I try to use the exposure group utility to split based on which movies it came from I end up with everything in the same group. The only ways I can see to do this is to either align the mics outside of cryosparc then import each group then and assign separately using using exposure group utilities… or import the movies as separate groups then align each group separately? weird. I must be missing something.
At Import time: When you import a dataset (movies, micrographs or particles) in cryoSPARC v2.12+, the set of imported data is automatically set with a new “exposure group ID”. This ID is unique within a project (the group ID increments with each import job, starting from zero) unless overridden using the Override Exposure Group ID parameter. Using this method, you can import your datasets separately based on their beam tilt groups, or any other groups where you would like to use, and the grouping of imports will be retained even if the datasets are merged later on in processing.
I didn’t know docs said it does that - I’ve only ever used the utility job to split them. It sounds like just re-running the imports with manual exposure IDs is the best workaround if this feature doesn’t actually work as advertised.
For splitting, I would guess you actually want “string_split” with a certain delimiter such as “_” instead of slice? As shown it would just look at the first character of the file name only.
Yeah I also tried using the “override exposure group ID” and imported the movies in that way, but it didn’t work. Ugh, frustrating.
For the splitting would that not split my images into groups based on what comes before the underscore? This is leginon data so the naming is not as useful as serialEM for beamtilt. I could rename each movie with a prefix “group1_” For example then import separate, then split with this tool, then re-assign each group manually. This is getting silly. Devs should be aware of this apparent bug… anyway, thanks Dan!
Non-informative file names seems like a Leginon design bug to me… (the automatic group thing should be fixed of course).
You can also specify which underscore-separated token to use for the groups. My files always look like da_Date_Button-Grid_NavItem_ShiftNo.mrc so using undescore and position 4 always works perfectly, with an offset of 9 (3x3 shifts), 18, etc. if I will be combining multiple datasets. With calibrated beam tilt compensation, the residual tilt is also really small, better than 0.02 mrad, and we don’t see an advantage in tilt refinement until very high resolutions beyond 2.5A. (The difference is largest for the highest resolution data, with our best apoferritin tests going from 2ish to 1.6A after CTF refinement).
Hi all, thanks for the reports here. We did find a bug where the exposure group ID was not carried over correctly if you used the CTFFIND4 or Gctf wrappers for the initial CTF Estimation. This will be fixed in an upcoming release.
Is anyone seeing this after using the Patch CTF job?