Well, we have the same issue with the NFS mount, i.e., after ~1500 movies 1 of 2 preprocessing workers stopped. Here is the output from that worker:
Overview:
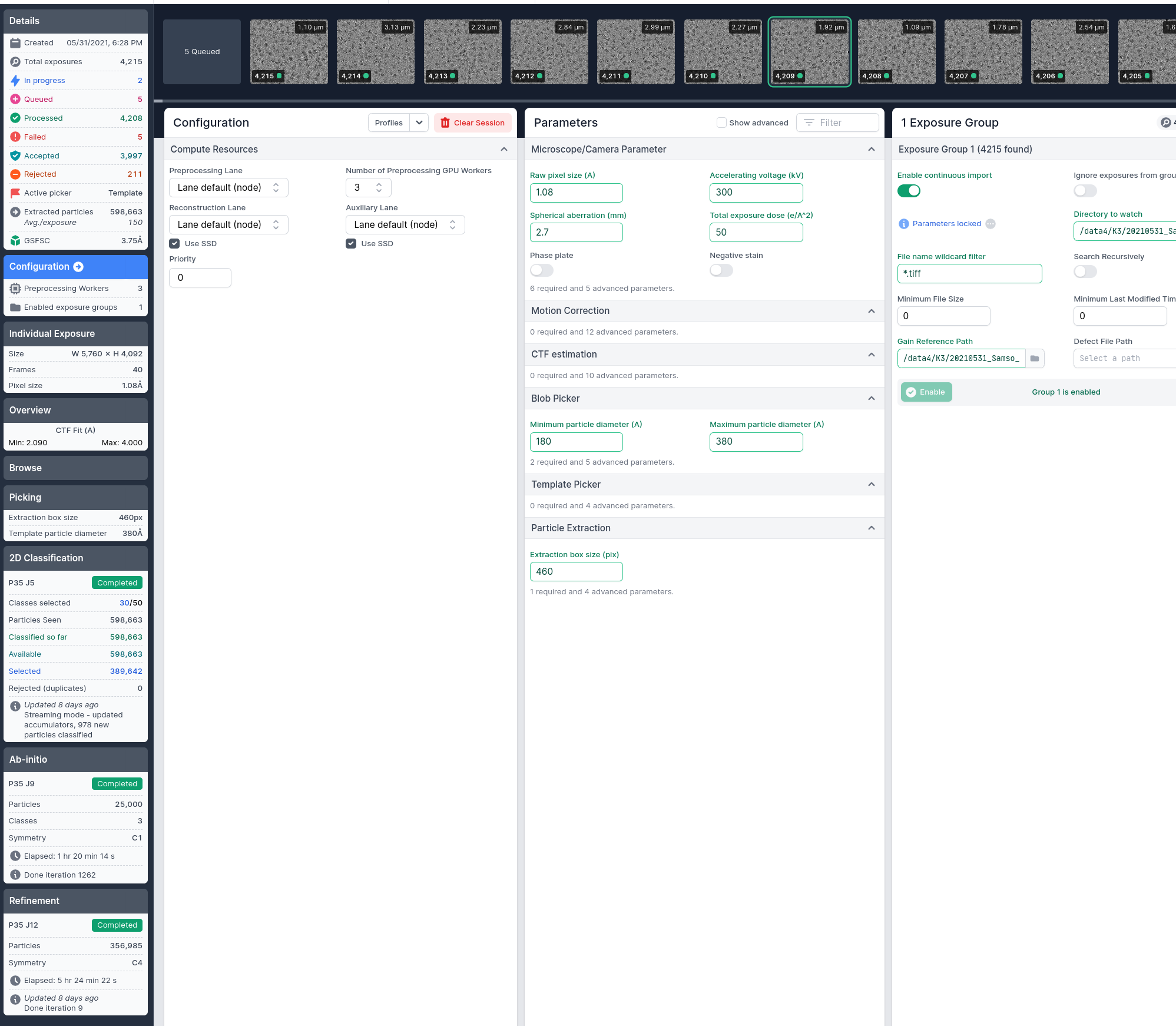
[CPU: 670.6 MB] PROCESSING EXPOSURE 1440 ===========================================================
[CPU: 670.6 MB] Reading exposure /data1/K3/20210622_xxx/raw/FoilHole_22406818_Data_22386506_22386508_20210622_205602_fractions.tiff and initializing .cs file…
Metadata:
{
"_id":{
"_str":"60d203035e783e01d5da882f"
},
"created_at":"2021-06-22T15:34:27.859Z",
"deleted":false,
"project_uid":"P46",
"status":"running",
"type":"rtp_worker",
"uid":"J2",
"workspace_uids":[
"W1"
],
"children":[
],
"cloned_from":null,
"parents":[
"J1"
],
"queue_message":null,
"title":"New Job J2",
"ui_tile_height":1,
"ui_tile_images":[
{
"name":"mic0",
"fileid":"60d287ce04683350ff20ef69",
"num_rows":1,
"num_cols":1
}
],
"ui_tile_width":1,
"job_type":"rtp_worker",
"completed_at":null,
"created_by_job_uid":null,
"created_by_user_id":"607f14dea30bf3defa66c693",
"description":"Enter a description.",
"failed_at":"2021-06-23T00:50:09.394Z",
"interactive":false,
"job_dir_size":0,
"killed_at":null,
"last_accessed":{
"name":"Purdy",
"accessed_at":"2021-06-23T13:21:37.567Z"
},
"launched_at":"2021-06-23T00:50:12.426Z",
"priority":0,
"queued_at":"2021-06-23T00:50:12.017Z",
"started_at":"2021-06-23T00:50:14.136Z",
"waiting_at":null,
"version":"v3.2.0",
"run_as_user":null,
"params_secs":{
"compute_settings":{
"title":"Compute settings",
"desc":"",
"order":0,
"name":"compute_settings"
}
},
"params_base":{
"session_uid":{
"type":"string",
"value":"S1",
"title":"cryoSPARC Live Session ID",
"desc":"",
"order":0,
"section":"compute_settings",
"advanced":false,
"hidden":false,
"name":"session_uid",
"is_default":false
},
"lane_name":{
"type":"string",
"value":"default",
"title":"cryoSPARC Live Lane Name",
"desc":"",
"order":1,
"section":"compute_settings",
"advanced":false,
"hidden":false,
"name":"lane_name",
"is_default":false
},
"interval":{
"type":"number",
"value":10,
"title":"cryoSPARC Live Exposure Search Interval",
"desc":"",
"order":2,
"section":"compute_settings",
"advanced":false,
"hidden":false,
"name":"interval",
"is_default":true
}
},
"params_spec":{
"session_uid":{
"value":"S1"
},
"lane_name":{
"value":"default"
}
},
"input_slot_groups":[
{
"type":"live",
"name":"live",
"title":"Live Session",
"description":"",
"count_min":0,
"count_max":1,
"repeat_allowed":false,
"slots":[
{
"type":"live.session_info",
"name":"session_info",
"title":"Session Info",
"description":"",
"optional":false
}
],
"connections":[
{
"job_uid":"J1",
"group_name":"live",
"slots":[
{
"slot_name":"session_info",
"job_uid":"J1",
"group_name":"live",
"result_name":"session_info",
"result_type":"live.session_info",
"version":"F"
}
]
}
]
}
],
"output_result_groups":[
],
"output_results":[
],
"output_group_images":{
"particles":"60d287ce04683350ff20ef6b"
},
"errors_build_params":{
},
"errors_build_inputs":{
},
"errors_run":[
],
"running_at":"2021-06-23T00:50:25.811Z",
"token_acquired_at":null,
"tokens_requested_at":null,
"last_scheduled_at":null,
"resources_needed":{
"slots":{
"CPU":6,
"GPU":1,
"RAM":2
},
"fixed":{
"SSD":false
}
},
"resources_allocated":{
"lane":"default",
"lane_type":"default",
"hostname":"xxx",
"target":{
"type":"node",
"lane":"default",
"name":"xxx",
"title":"Worker node xxx",
"desc":null,
"hostname":"xxx",
"ssh_str":"xxx",
"worker_bin_path":"/ws/local/progs/csparc/cryosparc_worker/bin/cryosparcw",
"""resource_slots""":{
"""CPU""":[
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31
],
"""GPU""":[
0,
1,
2,
3
],
"""RAM""":[
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15
]
},
"""resource_fixed""":{
"""SSD""":true
},
"""cache_path""":"/mnt/ssd970/",
"""cache_reserve_mb""":10000,
"""cache_quota_mb""":null,
"""monitor_port""":null,
"""gpus""":[
{
"""id""":0,
"""name""":"GeForce GTX 1080 Ti",
"""mem""":11721113600
},
{
"""id""":1,
"""name""":"GeForce GTX 1080 Ti",
"""mem""":11721506816
},
{
"""id""":2,
"""name""":"GeForce GTX 1080 Ti",
"""mem""":11721506816
},
{
"""id""":3,
"""name""":"GeForce GTX 1080 Ti",
"""mem""":11721506816
}
]
},
"""slots""":{
"""CPU""":[
0,
1,
2,
3,
4,
5
],
"""GPU""":[
0
],
"""RAM""":[
0,
1
]
},
"""fixed""":{
"""SSD""":false
},
"""license""":true,
"""licenses_acquired""":1
},
"""run_on_master_direct""":false,
"""queued_to_lane""":"""default""",
"""queue_index""":null,
"""queue_status""":null,
"""queued_job_hash""":null,
"""interactive_hostname""":"""xxx""",
"""interactive_port""":null,
"""PID_monitor""":16553,
"""PID_main""":16554,
"""PID_workers""":[
],
"""cluster_job_id""":null,
"""is_experiment""":false,
"""job_dir""":"J2",
"""experiment_worker_path""":null,
"""enable_bench""":false,
"""bench""":{
},
"""instance_information""":{
"""platform_node""":"""xxx""",
"""platform_release""":"3.10.0-1062.el7.x86_64",
"""platform_version""":""#1 SMP Wed Aug 7 18":"08":02 UTC 2019",
"""platform_architecture""":"x86_64",
"""physical_cores""":16,
"""max_cpu_freq""":2100,
"""total_memory""":"125.63GB",
"""available_memory""":"83.47GB",
"""used_memory""":"40.04GB",
"""gpu_info""":[
{
"""id""":0,
"""name""":"GeForce GTX 1080 Ti",
"""mem""":11721113600
}
],
"""CUDA_version""":"10.1.0"
},
"""project_uid_num""":46,
"""uid_num""":2,
"""ui_layouts""":{
"P46":{
"""show""":true,
"""floater""":false,
"""top""":232,
"""left""":1350,
"""width""":152,
"""height""":192,
"""groups""":[
]
},
"P46W1":{
"""show""":true,
"""floater""":false,
"""top""":232,
"""left""":1350,
"""width""":152,
"""height""":192,
"""groups""":[
]
}
},
"last_exported""":""2021-06-23T00":"50":11.992Z",
"queued_to_hostname""":false,
"queued_to_gpu""":false,
"no_check_inputs_ready""":false,
"num_tokens""":1,
"tokens_acquired_at""":1624409412.4197166,
"status_num""":25,
"progress""""\\"":[]}"