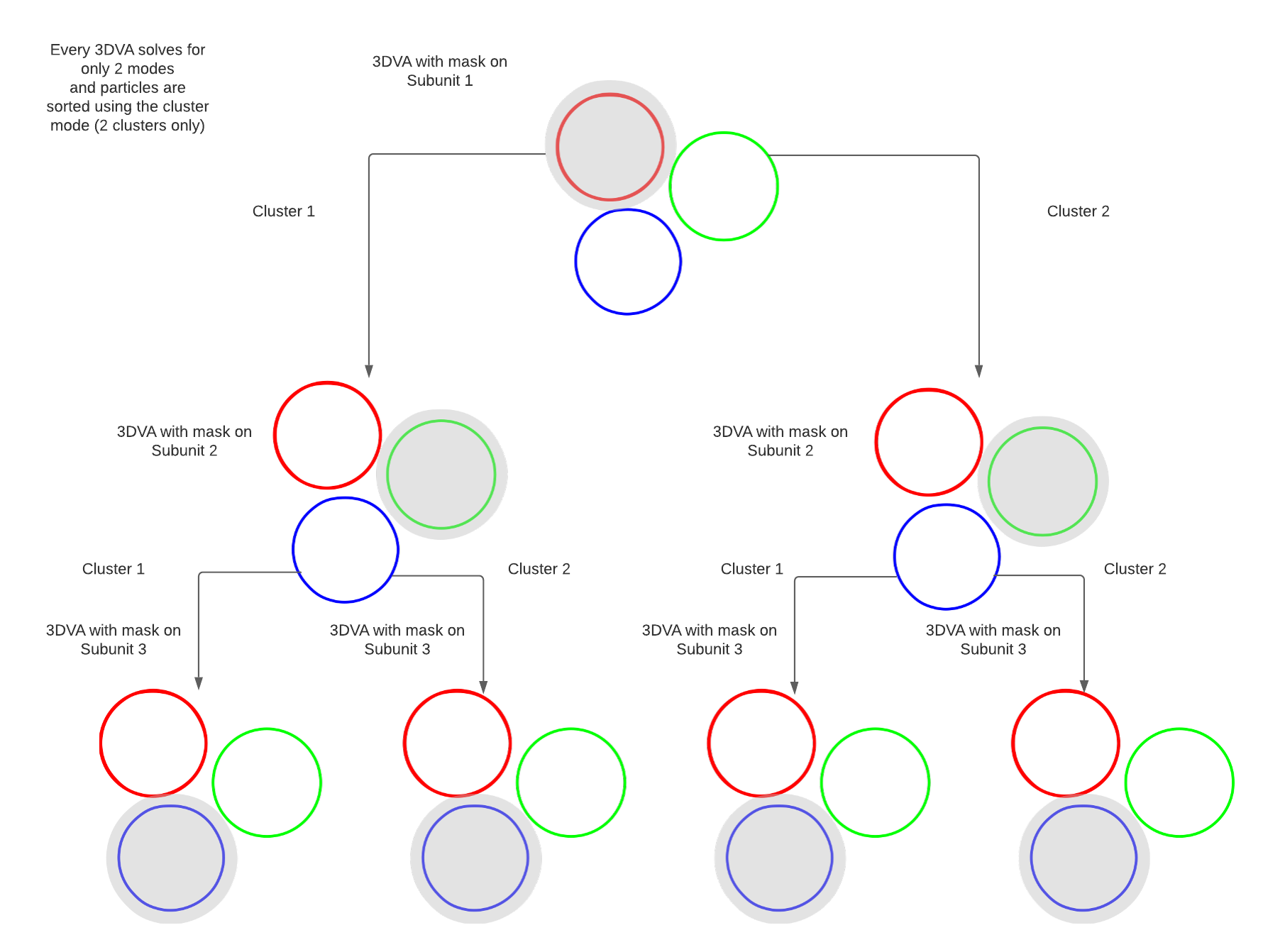
I’m new to using 3D variability and I seem to be conflating some concepts here. I’m trying to separate out distinct conformational states of a trimeric protein using 3DVA. The protein is a trimer and each monomer can independently exist in one of 2 conformations (A and B). The conformational state of any subunit does not preclude the either conformational state of the other two. My workflow is shown in the attached image. I’m dividing particles based on the assumption that each cluster contains a defined set of particles with a particular conformation (A or B) of the masked subunit. My results do suggest that all possible combinations of particles (AAA, AAB, BBB and so on…) exist in the dataset.
The question is I’m not sure if this the right way to do it nor am I sure how to confirm the presence of these conformations. Any suggestions?
Hi @vamsee,
This is quite interesting. I’m still thinking this through but if the following is true:
structure of monomer in state A is the same whether it’s found in an ABB, AAB, or AAA molecule (and likewise for B)
symmetry is “perfect” in the sense that the C3 symmetry is not substantially broken in ABB or AAB molecules
Then I think the right thing to do will actually be:
consensus refinement with C3 symmetry of all particles
symmetry expansion around C3 axis
create a mask around just one subunit
3DVA with mask of one subunit, using cluster mode to separate the A and B conformations
sort particles based on how many of the symmetry expanded copies were classified as A or B in the preceding step
each original particle was expanded into 3 new particles (representing each subunit). The expanded particles are classified based on the conformation of their single subunit that is within the mask. So they will come up AAA, AAB, ABB, or BBB
perform refinements of each set of particles from the four possible cases separately to confirm structures and resolutions for each (since the number of particles in each may be different)
Also, if the symmetry is not perfect, you can optionally do a round of local refinement with mask after step 3 above, to improve the alignments of all the subunits. But this may or may not help given the heterogeneity.
Also, for step 5 above, this will likely take some manual work directly reading .cs files so that you can see which particles came from where. Let us know if you are doing that and we can help.
The advantage of this symmetry expansion based method is that you only have to classify once, and you get the full power of the whole dataset during classification rather than subsets at each stage in the tree that you drew.