I installed cryosparc v 4.1.0 on new Rocky 8 workstation. While I ran the T20s extensive workflow fine, I cannot get beyond the patch motion correction jobs on my own data, though they initialize normally and typically process ~150 movies, the GPU’s fall off of the job with one process yielding the error code
"Child process with PID 1XXXX terminated unexpectedly with exit code -11." before the other encounters the same error, and terminates the job several movies later. update to v4.1.1 has not resolved the issue. Issue also occurs with Full-frame Motion correction and whether they are run with one or both GPUs.
From event log:
some information redacted to avoid identifying the project
Initialization
License is valid.
Launching job on lane default target jason-bourne …
Running job on master node hostname jason-bourne
[CPU: 196.6 MB]
Job J46 Started
[CPU: 196.6 MB]
Master running v4.1.1, worker running v4.1.1
[CPU: 196.6 MB]
Working in directory: /mnt/KRABBY-11/20221212_***/CS-20221212-***s/J46
[CPU: 196.6 MB]
Running on lane default
[CPU: 196.6 MB]
Resources allocated:
[CPU: 196.6 MB]
Worker: jason-bourne
[CPU: 196.6 MB]
CPU : [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
[CPU: 196.6 MB]
GPU : [0, 1]
[CPU: 196.6 MB]
RAM : [0, 1, 2, 3]
[CPU: 196.6 MB]
SSD : False
[CPU: 196.6 MB]
[CPU: 196.6 MB]
Importing job module for job type patch_motion_correction_multi…
[CPU: 235.0 MB]
Job ready to run
[CPU: 235.0 MB]
[CPU: 237.4 MB]
Job will process this many movies: 3846
[CPU: 237.4 MB]
parent process is 15503
[CPU: 179.4 MB]
Calling CUDA init from 15550
[CPU: 179.4 MB]
Calling CUDA init from 15551
The error
[CPU: 368.5 MB]
[CPU: 368.5 MB]
Processed 50 of 3846 movies in 339.78s
[CPU: 368.9 MB]
Child process with PID 15550 terminated unexpectedly with exit code -11.
[CPU: 364.4 MB]
[CPU: 364.4 MB]
Compiling job outputs…
[CPU: 364.4 MB]
Passing through outputs for output group micrographs from input group movies
[CPU: 364.4 MB]
This job outputted results [‘micrograph_blob_non_dw’, ‘micrograph_thumbnail_blob_1x’, ‘micrograph_thumbnail_blob_2x’, ‘micrograph_blob’, ‘background_blob’, ‘rigid_motion’, ‘spline_motion’]
[CPU: 364.4 MB]
Loaded output dset with 51 items
[CPU: 364.4 MB]
Passthrough results [‘movie_blob’, ‘gain_ref_blob’, ‘mscope_params’]
[CPU: 364.4 MB]
Loaded passthrough dset with 3846 items
[CPU: 364.4 MB]
Intersection of output and passthrough has 51 items
[CPU: 364.4 MB]
Passing through outputs for output group micrographs_incomplete from input group movies
[CPU: 364.4 MB]
This job outputted results [‘micrograph_blob’]
[CPU: 364.4 MB]
Loaded output dset with 3795 items
[CPU: 364.4 MB]
Passthrough results [‘movie_blob’, ‘gain_ref_blob’, ‘mscope_params’]
[CPU: 364.4 MB]
Loaded passthrough dset with 3846 items
[CPU: 364.4 MB]
Intersection of output and passthrough has 3795 items
[CPU: 364.4 MB]
Checking outputs for output group micrographs
[CPU: 364.4 MB]
Checking outputs for output group micrographs_incomplete
[CPU: 364.5 MB]
Updating job size…
[CPU: 364.5 MB]
Exporting job and creating csg files…
[CPU: 364.5 MB]
[CPU: 364.5 MB]
Job complete. Total time 370.13s
Log file output :

the command “uname -a && free -g && lscpu && nvidia-smi” yields the following:
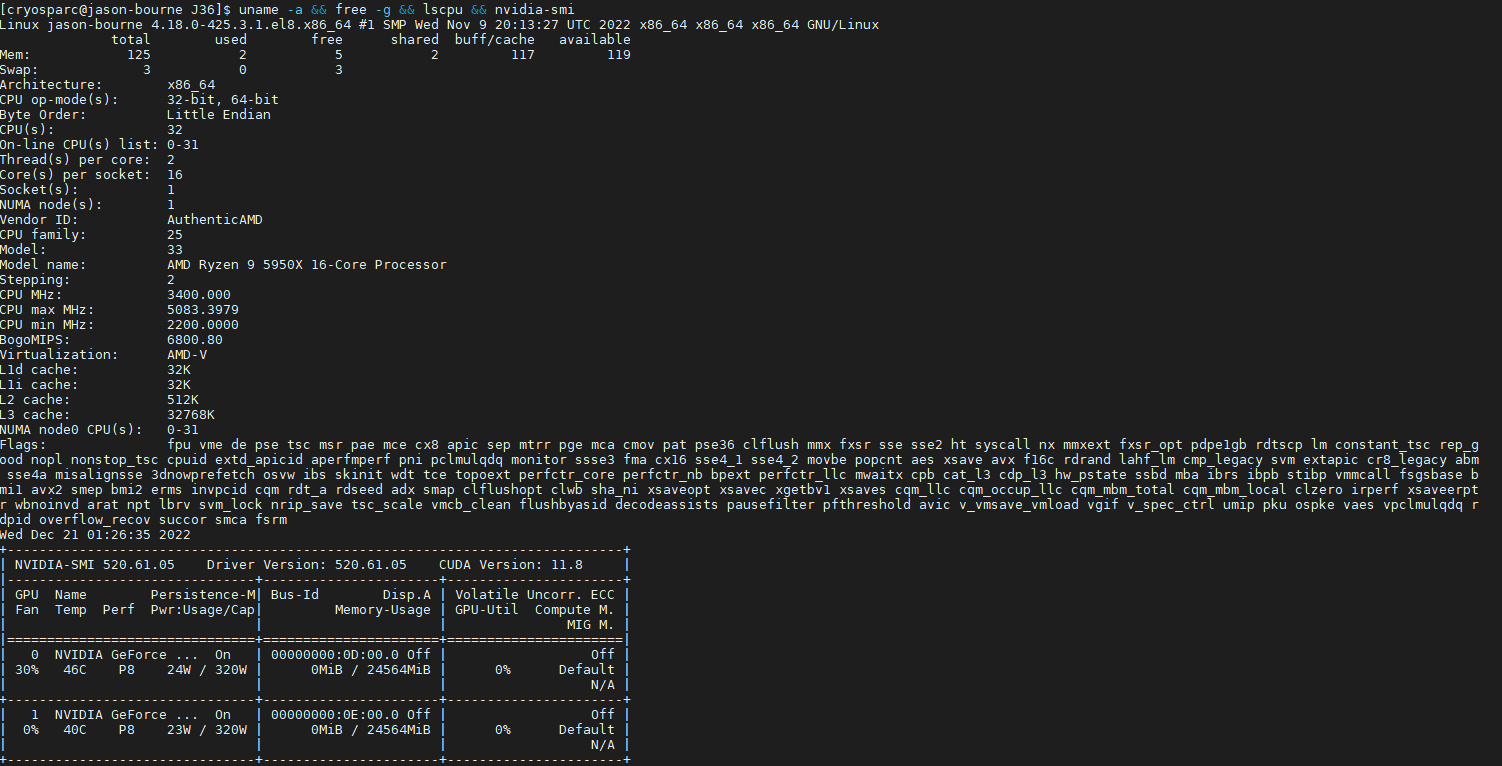
System specs are as follows: CPU: AMD Ryzen 5950X, GPUs 2x 3090Ti (limited to 320 Watts each), MOBO, X570 Taichi, RAM 128 GB DDR4, PSU 1200W.
Workstation is new so no comparison with previous cryosparc versions.
Not sure what may be causing GPU’s to initialize normally but subsequently fall off. Issue occurs running both or just one GPU. No obvious issues with system or GPU stability.
Any suggestions would be much appreciated!