Hello All,
It’s my first time using the Reference Based Auto Select 2D job, and I’m trying to understand how to best optimize the job and what to make of the results.
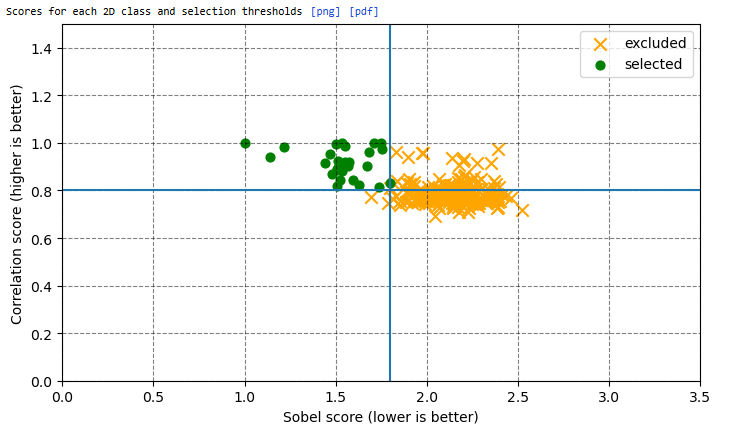
This is what the score distribution looks like.
There’s a very fine line between what’s accepted and what’s excluded, and from the class averages I can see that even those particles at the far edge of the excluded particles edge show some similarity to my reference volume. So to my eye, there seem to be class averages that may be good fits all throughout the distribution of excluded classes. Here are some examples:
this is right at the threshold:
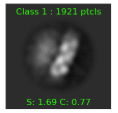
These are further away:

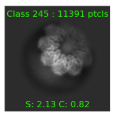

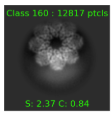
There is also one class which seems to be junk that got selected since it’s almost right at the threshold. Is there anything I could be tweaked to fix this and get rid of the junk class? Or is there just a very obscure view of the protein in it that I’m just not seeing?
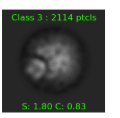
At what point could I conclude that I might have different species in the sample? What workflow would you advise to test that, if it is a feasible option?
Are there any other relevant parameters that could be changed to better score the classes, or should I instead just change the thresholds? The scores of these seemingly good-but-excluded classes are quite similar to scores of what seem to be actual junk classes, so adjusting the threshold will cause the junk classes to be included as well, which is why I’m hesitant to do that.
I also seem to have a lot off-centering even though I had the ‘re-center 2D classes’ parameter turned on. I’m rerunning the 2d classification job with ‘re-center mask binary’ turned on to see if this helps fix the issue. I’d still be grateful for any input on this if there are any other suggestions on what to do.
Thank you all in advance!