I have a very high density of particles, which I’m very excited about, but I am having some trouble finding 2D classification parameters where the classes don’t drift.
…but when I get to the 2D classification stage, things are not going very well. I think the problem is that the particle is very high symmetry, so the neighboring particles are essentially always in the same orientation, and reinforce in the averages, instead of averaging away:
or the averages will instead focus on the edge of a particle:
I want the particle density to be as high as possible in the micrographs, because I will get better CTF corrections, but I am somewhat at a loss as to how to solve this classification problem. I’ve tried playing with nearly every parameter available. I have:
Turned up COM threshold to 0.5, 0.75, and 0.9 with no changes
Tried COM binary
Turned off 2D recentering
Toggled on and off marginalize over poses, doesn’t seem to impact it
Changed batch size to 1000 (because I saw that sometimes good classes appear, but then later disappear)
Tried 40 iterations
Tried lowering uncertainty factor, since the initial picking looks pretty good
I’m then having a similar problem with homogenous refinement with symmetry enforced:
And real-space unfortunately smears out like it’s not actually aligning the particles well. I don’t think this would be an issue if I could get good 2D classes first.
Does anyone have experience, and any suggestions on how to handle datasets with particles packed this closely?
Thanks
This 2D class is very beautiful (though annoying, I’m sure!) - it looks like there is actual crystalline order here, at least on a local level.
Given that almost all of your picks are true particles (with the exception of some that are between the particles), have you tried proceeding directly to ab initio, or even to a consensus refinement if you have a map of a homolog with the same symmetry that can be used as an initial model?
Yes- I have been thinking of ways I could perhaps learn more about the crystalline order as well, perhaps by doing some tomography. It would be interesting to see the precise contacts in 3D.
So that was my first thought as well, but if I jump straight to ab-initio, I get basically a 3D version of what you see in that class (except now with an extreme preferred orientation problem).
The reason I did the 2D averaging with such a loose mask was actually to find particles that aren’t near any other particles, and use those for an ab-initio (see the last class in that image). I do get a basically round ball out of that which is a suitable initial model considering the tetrahedral symmetry. A refinement of just those ~100k particles goes to high resolution, but when I try to pull in the full ~3 million, using the refined model from that initial 100k, I get the two problems I detailed above. With dynamic masking, I get the neighboring particles, and with a static mask from the 100k refinement, it’s almost like the refinement just isn’t aligning and real-space is all washed out.
Perhaps the next thing to try is a static spherical mask with a soft edge?
Are you trying ab initio in C1, or with symmetry enforced? Often for high symmetry cases ab initio doesn’t work without symmetry enforced - it has a tendency to make pancakes.
If you know the symmetry I would recommend trying to enforcing it, and using an initial and final resolution on the high side (e.g. 9-7 Å)
Also maybe try a smaller box size for extraction - this won’t matter so much for 2D where you are using a mask, but it may do for ab initio
Are the resolution and map quality you get with this smaller set of particles sufficient to answer your question? If the answer to this question is yes, think about how much time you want to spend on the rest of the dataset. Not saying you should give up on it, but that could help you set priorities.
One possibly crazy idea, but I would be curious to see what happens: maybe try using the 2D class average Oli showed (the one in which the hexagonal packing of multiple complexes shows up very well), for template picking. Try to find a large enough inter-particle distance that gives no overlapping picks (and therefore overall much fewer picks). You could then extract with a box size adequate to not enclose too much surrounding particles, and choose a mask diameter for class2D that is just wide enough to enclose one hexagonal “tile” (with 7 particles in total: one in the center surrounded by 6). If these “tiles” are homogeneous enough, they should drive the alignment much more strongly than single particles accidentally enclosed near the edges of the box.
Also be sure to remove duplicates (especially if you have a workflow that skips 2D classification, which does it automatically now). High symmetry + high density + duplicated particles = guaranteed overrefinement, either preventing a good structure entirely or at least making uninterpretable FSC curves.
A large part of my goal is to see how far I can push our Arctica, and expose where the bottlenecks are in our system. After seeing how well the protein froze, and that it’s significantly smaller than Ferritin, I thought it might make an interesting target for high-resolution.
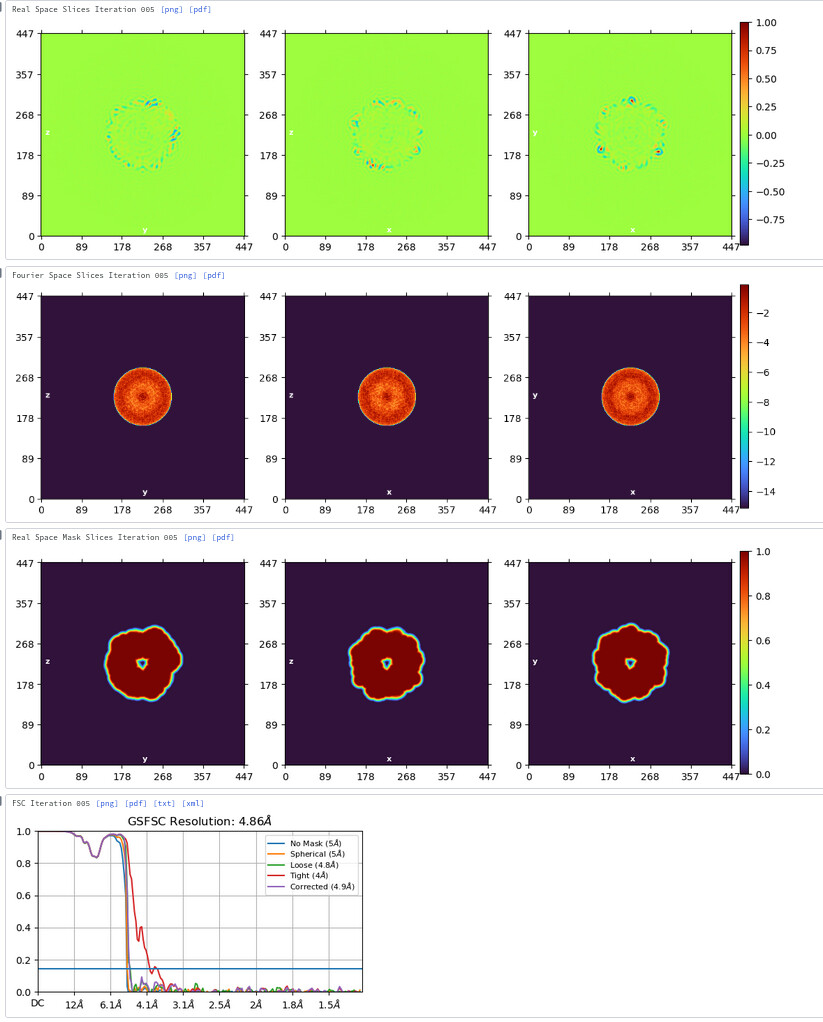
Currently, those tiles are going to very high resolution:
But I have no had time to try and fit the atomic model into them yet, so it’s tough for me to really gauge the quality of the map. The closer the map is to the central point, the better the quality, so I think I need to actually expand the particle size even larger. However, CryoSPARC is reporting ~3 Å resolution. I will update here when I have made more progress on that.
I’m not super well-versed on duplicate particles, other than having seen that they can cause weird FSC artifacts such as preventing them from reaching zero. Obviously, they’re undesirable since they’ll reinforce noise, but I’m curious if something like the CryoSPARC “Remove Duplicates” job would be sufficient?
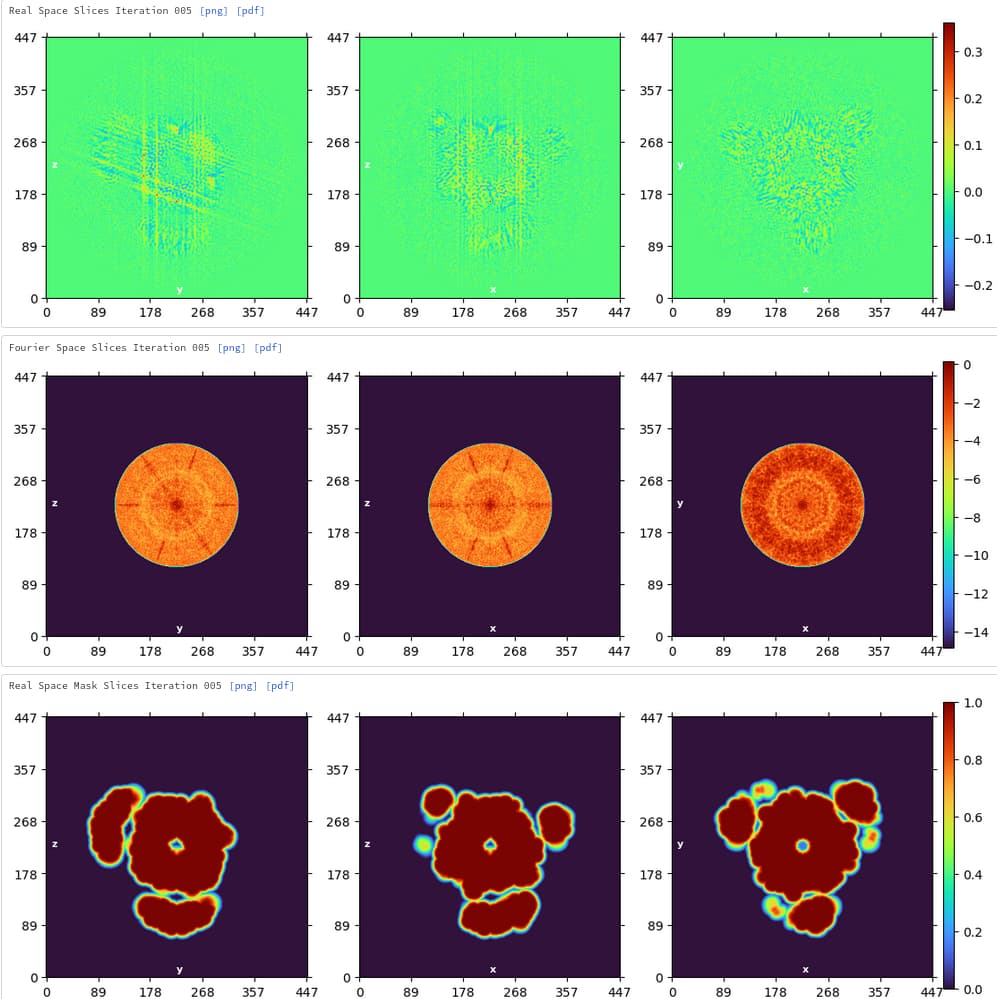
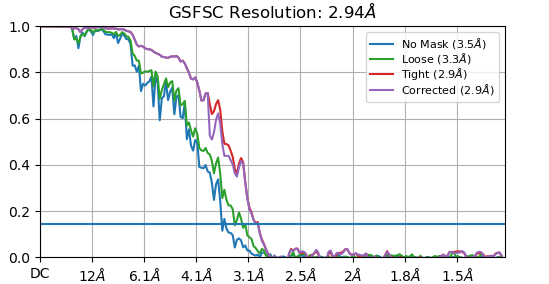
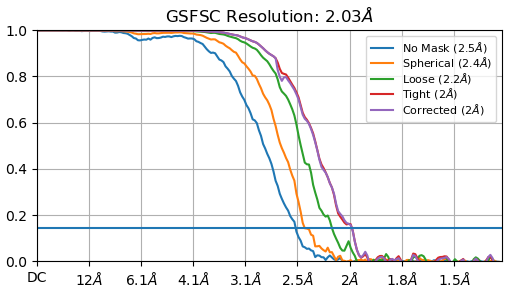
So I wound up trying a number of different strategies, and while I haven’t found anything perfect yet, I have found a rough solution that’s gotten me pretty far (down to 2.03 Å with ~1/10th the data so far). Basically, I did a 2D classification of the data with 200 classes, and class certainty set to 1. That gave me a very small subset of particles (~30,000) that weren’t participating in those hexagonal arrays. That let me get a decent ab initio and homogenous refinement to ~3 Å. From there, I took the raw extracted particles, and dumped those right into a homogenous refinement with the dynamic mask threshold set pretty high (0.35 but I might go even higher). After a couple of iterations of that, the outlying six particles does in-fact get masked out pretty well.
The resolution was relatively poor (~ 3 Å) and the FSC not great:
But, after that, the 2D classification worked much better using those particles, and settings meant to keep them from drifting, and I was able to successfully isolate and classify about 40% of the input particles.
You don’t seem to have side views though, at least in everything you have shown so far. Do you have any and simply haven’t shown them? Or do you get such good reconstructions with only these top views? I am curious to know, because I have been helping a colleague with a similar lack of one view of a different, but similarly shaped particle (flat because much shorter in one direction than in the two others). Except for him it’s the opposite: he sees mostly side views and very few top views.
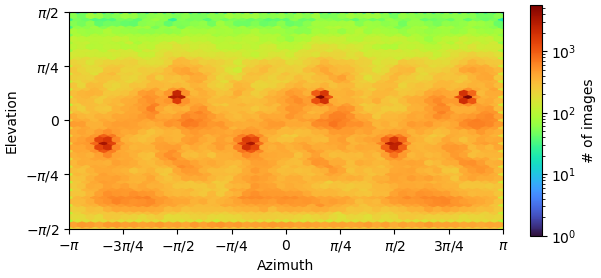
It’s fairly spherical and with tetrahedral symmetry, so two-fold axes along each face and three-fold axes along the body diagonals. In theory, I think I should be fine with one view of the three fold ± some rotation perpendicular to the three fold axes. I am a little concerned about preferred orientation because of the crystal packing, but so far the ThreeDFSC looks pretty consistent regardless of the orientation, as well as CryoSPARC’s viewing direction chart:
We will see as I get the whole dataset incorporated.
Just a small update, I did some Topaz picking on 100 micrographs, and it got much closer to good classes. Still not quite perfect, they aren’t really centering well, but it’s way better than what I had before: