Got two feature requests, both related to improving handling of changes in CTF aberrations over time. I’ve noticed that accounting for this is usually what it takes for me to eek out an extra 0.1-0.3Å of resolution in our benchmark datasets. Not sure how much this will impact datasets in general- but thought it is interesting observation to note.
The first feature request is to allow splitting particles into different exposure groups by # of target groups. Either by micrograph or particles.
The second request (and this one is way more cuckoo, take with a grain of salt), would be to implement global CTF refinement as a binary tree, with the CTF aberrations being fit in progressively smaller subgroups until some kind of fitting quality threshold is hit. This might be used to identify discontinuities in the aberrations by way of ~binary search, and/or identify and fit gradual progressions over time, like a CTF aberration equivalent to motion correction.
Cheers! and many thanks for such an awesome piece of software!
The first would be very useful, the second incredibly so but likely quite expensive in terms of time.
For data collected with EPU, and read directly from storage, something similar to Dustin Morado’s AFIS script which looks at the paired .xml file and created exposure groups based on beam tilt would be great as well - I’ve found EPU tends to output a 7x7 grid with each edge having a final 5 groups (for a total of 69). This is reproducible across dozen of datasets acquired with beam shift acquisition at several magnifications and shots-per-hole, so a “target number of exposure groups” would be nice (shifts on a per hole basis don’t seem to make much if any difference until hitting <1.4 Å). A graceful failure method would be needed (if no .eer or .xml, do not attempt to import) as I’ve found EPU can occasionally screw up saving all relevant files if stopping a run early…
For data collected with SerialEM, obviously naming schemes are a little easier to control so it’s easier to split up.
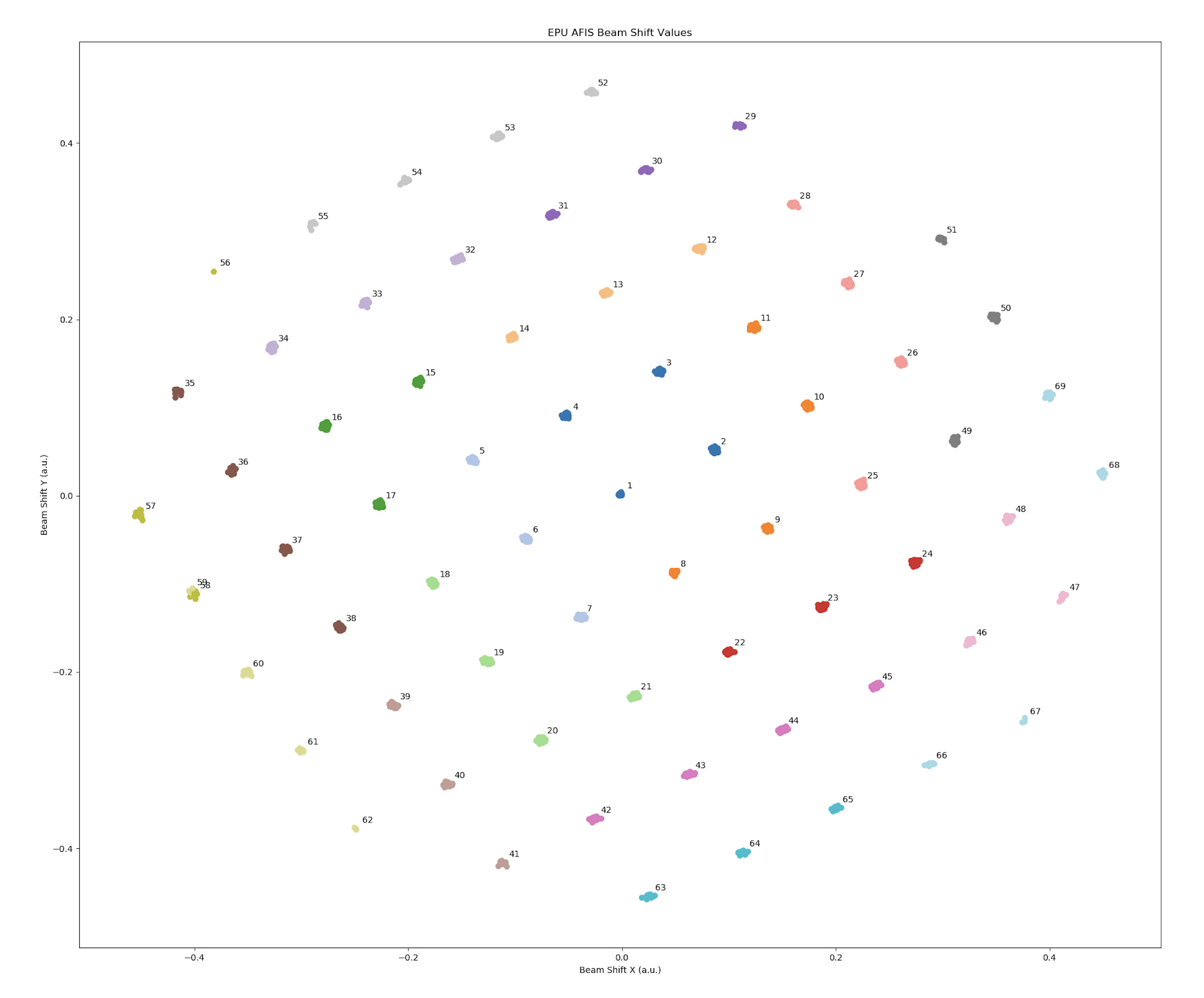
No, I mean that the grouping may need to be guided on how many groups is appropriate. Below is an example with 69 groups. Note 58 and 59 are in the same spot, so I merged them manually as the AFIS script didn’t want to, for a total of 68 groups. Specify a non-optimal number (too low) the EPU AFIS script will group different tilt angles in the same optics group, which can result in… oddities in the tilt estimates in RELION.
This is single shot-per-hole. Subgrouping by time (e.g.: the first half of exposures at any given tilt are one group, the second half is another group) may be useful for very long acquisition runs. Or with a CFEG perhaps flash timings; but as far as I know this is harder to do as EPU doesn’t output this information and it has to be recovered manually. But having a group for each tilt within a hole when using 2-8 shots-per-hole doesn’t make much difference.
Does that script use k-means to cluster the image shifts? With the constraint that the clusters look like this kind of grid there are more robust (in choice of k) ways to do it.
BTW, SerialEM shift values look similar to this, but in practice we just put the pattern position into the filenames as it is much easier to work with. For ad-hoc shifts from Leginon, then they’re all over the place, then all you can do is group them by similarity using k-means or similar.
That’s what I meant, but fudging slightly on the group sizes to keep them ~ more consistent. Splitting by every N particles could result in splitting particles within a single image into separate groups… but I don’t think that would necessarily be a disaster.
The reason I suggested this first is because it should be relatively easy to implement- I can do something somwaht similar by using the regex tokenization and the file names- but this is a bit coarse if splitting by decimal position, ie. I can choose to break an 8000 micrograph dataset into 8, 80, or 800 groups just based on string tokenization.
To @rbs_sci suggestion, I’ve accomplished grouping by IS by saving the image shift position in the filename in SerialEM and using the same filename tokenization.
Yes, I know grouping by image shift with data collected in SerialEM is easy - as I said in the last sentence of my first post, it can be done in the filename. Which is great for SerialEM. EPU, however, does not permit custom naming schemes.
By default the AFIS script uses kmeans, yes. It offers a second option, Heirarchical Ascendant Clustering, which I use exclusively as I’ve found kmeans to group in extremely non-optimal ways when using high shots-per-hole, while HAC gets it “right” 99.9% of the time.
@rbs_sci After the agglomerative clustering you could merge clusters with centroids within a threshold distance of each other (if agglomerative is still splitting those overlapped clusters). Maybe 2/3 the distance between hole centers or so?
@yoshiokc Still not quite sure what you mean. I used to split up shift groups, say for a 3x3 hole pattern, by taking the _001.tif part of the SerialEM filenames and taking it modulo 9. But then after the advent of the hole combiner we started having incomplete shift groups, so it was necessary to use the shift position/hole number which looks like e.g. X+1Y-1-2 (the _00X part is just sequential, _006 in from one target is not necessarily _006 from another target). For that I use a regex that I copy and paste. Maybe we’re on the same page?
@DanielAsarnow, I was just suggesting an additional option to split by micrograph or particles, into ~N groups. the groups would likely not be perfectly split, exact same size, but I don’t think that would matter that much.
had an additional thought, perhaps the heuristic to descend into an additional subdivision of the “exposure group tree” could be the extent or residual phase error still present after fitting? ie. you’d maintain the residual error of all the exposure groups in a heap and split and re-fit the top entry? A merge pass might also do the opposite, re-merge groups after splits as long as the merged group scores better than the individual ones: this might find and restore groups related by things like image shift, while the above would hunt down temporal discontinuities in the entire dataset.
You may be interested to know that we have now implemented exposure group clustering via beam shift in the Exposure Group Utilities job, for data collected via EPU.
For your original first feature request, would the criteria to split micrographs into exposure groups be based on the collection timestamp of the micrograph, such that micrographs are “batched” into exposure groups based on the time they were collected at?
My initial suggestion was to do so by time (or exposure # as a proxy). What I had noticed from my higher-resolution ApoFe dataset refinements in Relion (~1.3Å) was that the next biggest improvement in GSFSC was after grouping by time groups rather than by IS groups. Using the coma vs. IS correction in SerialEM, and rather modest shifts (we rarely go above ~4um) I just didn’t see very big improvements from breaking the datasets into IS groups (think 1.56 → 1.52 type of improvements)