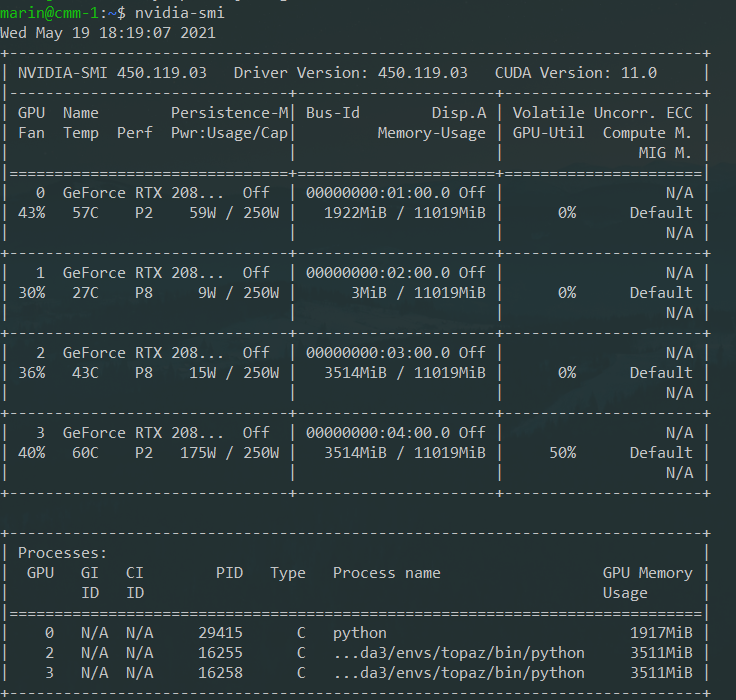
nvidia-smi:
Job log (obtained with cryosparcm joblog P3 J215 > log.txt):
================= CRYOSPARCW ======= 2021-05-19 18:18:28.238449 =========
Project P3 Job J215
Master cmm-1 Port 39002
===========================================================================
========= monitor process now starting main process
MAINPROCESS PID 2473
MAIN PID 2473
deep_picker.run_deep_picker cryosparc_compute.jobs.jobregister
========= monitor process now waiting for main process
2021-05-19 18:18:34.832676: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
========= sending heartbeat
2021-05-19 18:19:22.589079: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-05-19 18:19:22.621872: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcuda.so.1
2021-05-19 18:19:22.670988: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-19 18:19:22.671739: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce RTX 2080 Ti computeCapability: 7.5
coreClock: 1.545GHz coreCount: 68 deviceMemorySize: 10.76GiB deviceMemoryBandwidth: 573.69GiB/s
2021-05-19 18:19:22.671886: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-19 18:19:22.672556: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 1 with properties:
pciBusID: 0000:02:00.0 name: GeForce RTX 2080 Ti computeCapability: 7.5
coreClock: 1.545GHz coreCount: 68 deviceMemorySize: 10.76GiB deviceMemoryBandwidth: 573.69GiB/s
2021-05-19 18:19:22.672628: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-19 18:19:22.673253: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 2 with properties:
pciBusID: 0000:03:00.0 name: GeForce RTX 2080 Ti computeCapability: 7.5
coreClock: 1.545GHz coreCount: 68 deviceMemorySize: 10.76GiB deviceMemoryBandwidth: 573.69GiB/s
2021-05-19 18:19:22.673331: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-05-19 18:19:22.673948: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 3 with properties:
pciBusID: 0000:04:00.0 name: GeForce RTX 2080 Ti computeCapability: 7.5
coreClock: 1.545GHz coreCount: 68 deviceMemorySize: 10.76GiB deviceMemoryBandwidth: 573.69GiB/s
2021-05-19 18:19:22.674004: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-05-19 18:19:22.853563: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-05-19 18:19:22.853750: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-05-19 18:19:22.871436: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2021-05-19 18:19:22.871843: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2021-05-19 18:19:23.108518: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2021-05-19 18:19:23.108983: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcusparse.so.11'; dlerror: libcusparse.so.11: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/cryosparc/cryosparc_worker/cryosparc_compute/blobio:/opt/cryosparc/cryosparc_worker/cryosparc_compute/libs:/opt/cryosparc/cryosparc_worker/deps/external/cudnn/lib:/usr/local/cuda/lib64:/opt/cryosparc/cryosparc_master/cryosparc_compute/blobio:/opt/cryosparc/cryosparc_master/cryosparc_compute/libs
2021-05-19 18:19:23.131132: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-05-19 18:19:23.131198: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1757] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
***************************************************************
Running job on hostname %s cmm-1
Allocated Resources : {'fixed': {'SSD': False}, 'hostname': 'cmm-1', 'lane': 'default', 'lane_type': 'default', 'license': True, 'licenses_acquired': 1, 'slots': {'CPU': [2], 'GPU': [1], 'RAM': [5, 6]}, 'target': {'cache_path': '/data/cryosparc_cache', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'gpus': [{'id': 0, 'mem': 11554717696, 'name': 'GeForce RTX 2080 Ti'}, {'id': 1, 'mem': 11554717696, 'name': 'GeForce RTX 2080 Ti'}, {'id': 2, 'mem': 11554717696, 'name': 'GeForce RTX 2080 Ti'}, {'id': 3, 'mem': 11554717696, 'name': 'GeForce RTX 2080 Ti'}], 'hostname': 'cmm-1', 'lane': 'default', 'monitor_port': None, 'name': 'cmm-1', 'resource_fixed': {'SSD': True}, 'resource_slots': {'CPU': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17], 'GPU': [0, 1, 2, 3], 'RAM': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]}, 'ssh_str': 'cryosparcuser@cmm-1', 'title': 'Worker node cmm-1', 'type': 'node', 'worker_bin_path': '/opt/cryosparc/cryosparc_worker/bin/cryosparcw'}}
**** handle exception rc
set status to failed
========= main process now complete.
========= monitor process now complete.