Hi @wtempel, I am not sure what @prash means by “using a lower patch size” in that suggestion?
@prash Would you like to elaborate on how you made this work?
@wtempel @gha @eMKiso Sorry for the delay. Looks like the term ‘patch size’ is now called ‘Shape of split micrographs’ in the recent version of CryoSPARC. I lower to down from 256 to 64 to make it work.
1 Like
I experience the same issue with the Deep Picker Inference:
[CPU: 214.6 MB Avail: 50.99 GB]
Importing job module for job type deep_picker_inference…
[CPU: 538.8 MB Avail: 50.81 GB]
Job ready to run
[CPU: 538.8 MB Avail: 50.81 GB]
[CPU: 540.3 MB Avail: 50.81 GB]
Using TensorFlow version 2.8.4
[CPU: 540.3 MB Avail: 50.81 GB]
Processing micrographs and inferring particles…
[CPU: 540.3 MB Avail: 50.81 GB]
Loading model…
[CPU: 540.3 MB Avail: 50.81 GB]
Loaded model.
[CPU: 540.3 MB Avail: 50.81 GB]
0/103 micrographs processed.
[CPU: 1.09 GB Avail: 50.37 GB]
Traceback (most recent call last):
File “cryosparc_master/cryosparc_compute/run.py”, line 95, in cryosparc_master.cryosparc_compute.run.main
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/run_deep_picker.py”, line 531, in cryosparc_master.cryosparc_compute.jobs.deep_picker.run_deep_picker.run_deep_picker_inference
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 830, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 835, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 755, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker._do_picking
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 521, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.get_dataset_from_particle_centers
ValueError: need more than 1 value to unpack
Training works fine and the diagnostic plots look good/as expected from successful training.
The “shape of split micrographs” approach does not work but results (naturally) in a significant increase in running time. The issue appears to come up quite frequently and has so far not been solved, at least judging what I see in the forum. Can someone provide support/help please?
Welcome to the forum @D_E_N_N_I_S .
Please can you confirm that this workaround did not work, and if it did not work, post the value specified for Shape of split micrographs, as well as excerpts form the Event Log and the job log (Metadata|Log) for the corresponding job.
Thank you!
Sorry for the late reply, several things came up in between…
Below I more comprehensive error/problem description.
I have a set of about 100 micrographs, imported them, curated the exposures, picked manually about 500 particles from 10 micrographs.
Next, I connected the output of the Manual Particle Picker Job to a Deep Train Job (Micrographs and Particles).
The Training of the Deep Picker I have done with default parameters, except for the parameter named “Shape of split micrographs”, this parameter I have tested for either 256, 128, and 64.
The Deep Train Job finished without any errors or warnings and the training reached acceptable accuracy and resulted in expected diagnostic curves, see the following image.
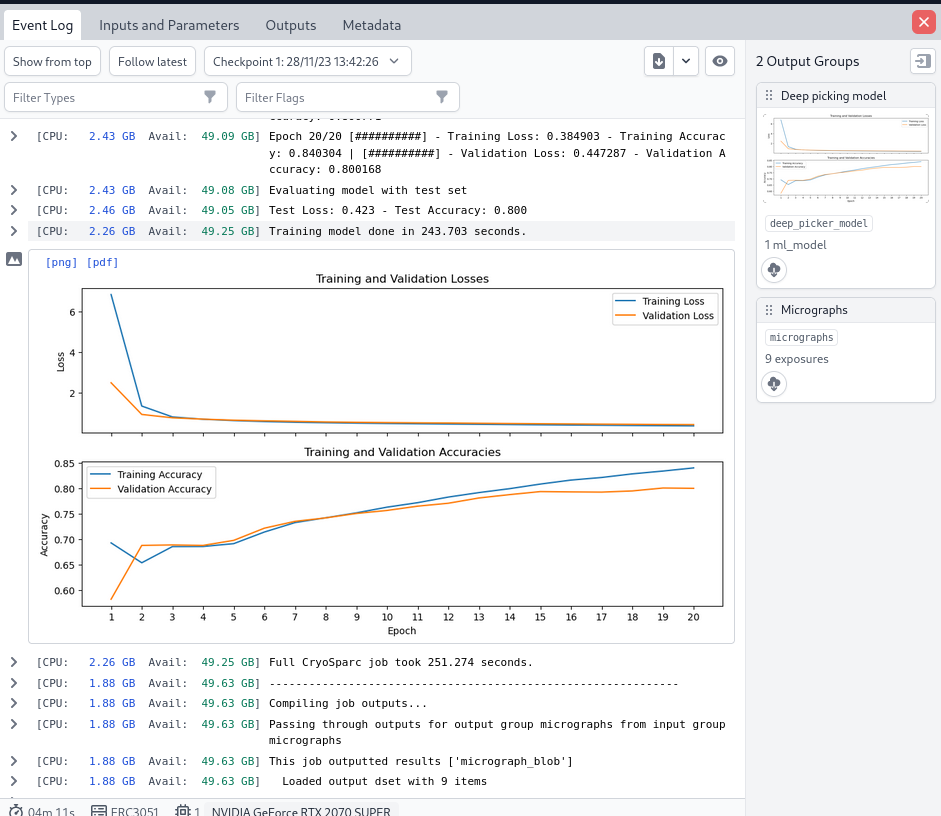
Next, I moved on to the Deep Picker Inference Job, employing the model just trained. For this I inputted the curated exposures (100 micrographs, from the curated exposure job) and the model from the Deep Picker Train Job to the Deep Picker Inference Job. It is only then when I experienced the error so frequently reported in the forum, despite the different settings of the parameter “Shape of split micrographs” is the Deep Picker Train Job.
[CPU: 214.6 MB Avail: 50.99 GB]
Importing job module for job type deep_picker_inference…
[CPU: 538.8 MB Avail: 50.81 GB]
Job ready to run
[CPU: 538.8 MB Avail: 50.81 GB]
[CPU: 540.3 MB Avail: 50.81 GB]
Using TensorFlow version 2.8.4
[CPU: 540.3 MB Avail: 50.81 GB]
Processing micrographs and inferring particles…
[CPU: 540.3 MB Avail: 50.81 GB]
Loading model…
[CPU: 540.3 MB Avail: 50.81 GB]
Loaded model.
[CPU: 540.3 MB Avail: 50.81 GB]
0/103 micrographs processed.
[CPU: 1.09 GB Avail: 50.37 GB]
Traceback (most recent call last):
File “cryosparc_master/cryosparc_compute/run.py”, line 95, in cryosparc_master.cryosparc_compute.run.main
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/run_deep_picker.py”, line 531, in cryosparc_master.cryosparc_compute.jobs.deep_picker.run_deep_picker.run_deep_picker_inference
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 830, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 835, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 755, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker._do_picking
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 521, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.get_dataset_from_particle_centers
ValueError: need more than 1 value to unpack
Output from metadata tab (log file):
================= CRYOSPARCW ======= 2023-11-28 13:57:07.765953 =========
Project P100 Job J98
Master redacted
===========================================================================
========= monitor process now starting main process at 2023-11-28 13:57:07.765982
MAINPROCESS PID 3681204
MAIN PID 3681204
deep_picker.run_deep_picker cryosparc_compute.jobs.jobregister
========= monitor process now waiting for main process
2023-11-28 13:57:13.472433: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.472600: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.484277: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.484461: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.484587: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.484774: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.485124: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-11-28 13:57:13.485766: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.485924: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.486045: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.551624: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.551816: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.551938: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-11-28 13:57:13.552039: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 128 MB memory: -> device: 1, name: NVIDIA GeForce RTX 2070 SUPER, pci bus id: 0000:02:00.0, compute capability: 7.5
/Local/cryosparc/cryosparc2_worker_remote/cryosparc_compute/jobs/motioncorrection/mic_utils.py:95: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0.
@jit(nogil=True)
/Local/cryosparc/cryosparc2_worker_remote/cryosparc_compute/micrographs.py:563: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0.
def contrast_normalization(arr_bin, tile_size = 128):
WARNING:tensorflow:Error in loading the saved optimizer state. As a result, your model is starting with a freshly initialized optimizer.
2023-11-28 13:57:18.427791: I tensorflow/stream_executor/cuda/cuda_dnn.cc:368] Loaded cuDNN version 8700
========= sending heartbeat at 2023-11-28 13:57:20.660539
2023-11-28 13:57:23.562697: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 302.29MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-11-28 13:57:23.562744: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 302.29MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-11-28 13:57:23.623509: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 548.13MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-11-28 13:57:23.623556: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 548.13MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-11-28 13:57:23.635687: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 88.00MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-11-28 13:57:23.635723: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 88.00MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-11-28 13:57:23.643030: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 592.14MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-11-28 13:57:23.643065: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 592.14MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-11-28 13:57:23.663594: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 548.16MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-11-28 13:57:23.663628: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 548.16MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
***************************************************************
Running job on hostname redacted
Allocated Resources : {'fixed': {'SSD': False}, 'hostname': 'redacted, 'lane': 'ERC3051', 'lane_type': 'node', 'license': True, 'licenses_acquired': 1, 'slots': {'CPU': [], 'GPU': [1], 'RAM': [1]}, 'target': {'cache_path': '/Local/cryosparc/cryosparc_scratch/', 'cache_quota_mb': None, 'cache_reserve_mb': 10000, 'desc': None, 'gpus': [{'id': 0, 'mem': 8359378944, 'name': 'NVIDIA GeForce RTX 2070 SUPER'}, {'id': 1, 'mem': 8361738240, 'name': 'NVIDIA GeForce RTX 2070 SUPER'}], 'hostname': 'redacted', 'lane': 'ERC3051', 'monitor_port': None, 'name': 'redacted', 'resource_fixed': {'SSD': True}, 'resource_slots': {'CPU': [0, 1, 2, 3, 4, 5, 6, 7], 'GPU': [0, 1], 'RAM': [0, 1, 2, 3, 4, 5, 6, 7]}, 'ssh_str': 'redacted', 'title': 'redacted', 'type': 'node', 'worker_bin_path': '/Local/cryosparc/cryosparc2_worker_remote/bin/cryosparcw'}}
**** handle exception rc
Traceback (most recent call last):
File "cryosparc_master/cryosparc_compute/run.py", line 95, in cryosparc_master.cryosparc_compute.run.main
File "cryosparc_master/cryosparc_compute/jobs/deep_picker/run_deep_picker.py", line 531, in cryosparc_master.cryosparc_compute.jobs.deep_picker.run_deep_picker.run_deep_picker_inference
File "cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py", line 830, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File "cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py", line 835, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File "cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py", line 755, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker._do_picking
File "cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py", line 521, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.get_dataset_from_particle_centers
ValueError: need more than 1 value to unpack
set status to failed
========= main process now complete at 2023-11-28 13:57:24.522314.
========= monitor process now complete at 2023-11-28 13:57:24.526035.
What Boszlacs (and potentially gha) describe is the same as what I am experiencing, most likely the same cause/underlying reason for this error.
I can confirm that the workaround suggested by prash did not work for me, aside from the fact that so far I have not come to understand how this parameter addresses the raised issue. Before I start diving into the utilitis script of the deep picker, I wanted to first consult the CryoSPARC discussion/forum.
Please let me know if more information is required. Working with the Deep Picker of CryoSPARC appears to be difficult. Talking to other colleagues, the notion seems to be that many have troubles to get it to run and have refrained from it. Since the Training looks quite promising, I am motivated to get the Deep Picker to work, even just for curiosity of its performance compared to alternatives.
This time I will try to remain engaged and respond timely.
Thanks again and best regards
Dennis
Hi @D_E_N_N_I_S.
Unfortunately, we are not sure what caused this error. May I suggest Topaz (github, wrapper docs) as an alternative approach for deep picking.
Ok, nonetheless, thank you for looking into it.
Actually, I have already tested Topaz and found it to perform not well. The training statistics already indicated poor performance of Topaz. Currently I am with crYOLO which performs much better than Blob, Template, Filament tracer, and Topaz. Only the Deep Picker I have not tested, since its training looked so promising, I wanted to test it. But the effort to get it to run seems not worth it anyway…
Thanks again!
Dennis
Hello,
I have the same problem with my data set. Can’t tell if it works with other data. I tried 256, 128 and 64 for the shape of split mics, different numbers of images in the training set. still get the same error in the inference job.
the log file contains the following:
2024-01-17 20:03:23.392579: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2024-01-17 20:03:23.392866: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2024-01-17 20:03:23.393593: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-01-17 20:03:23.403736: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2024-01-17 20:03:23.404184: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2024-01-17 20:03:23.404478: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2024-01-17 20:03:23.841395: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2024-01-17 20:03:23.841806: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2024-01-17 20:03:23.842136: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2024-01-17 20:03:23.842414: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 128 MB memory: → device: 0, name: NVIDIA GeForce RTX 3090, pci bus id: 0000:81:00.0, compute capability: 8.6
/home/cryosparc_user/cryosparc/cryosparc_worker/cryosparc_compute/jobs/motioncorrection/mic_utils.py:95: NumbaDeprecationWarning: The ‘nopython’ keyword argument was not supplied to the 'numba.jit
’ decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See Deprecation Notices — Numba 0+untagged.4124.gd4460fe.dirty documentation
deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
@jit(nogil=True)
/home/cryosparc_user/cryosparc/cryosparc_worker/cryosparc_compute/micrographs.py:563: NumbaDeprecationWarning: The ‘nopython’ keyword argument was not supplied to the ‘numba.jit’ decorator. The im
plicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See Deprecation Notices — Numba 0+untagged.4124.gd4460fe.dirty documentation for details.
def contrast_normalization(arr_bin, tile_size = 128):
WARNING:tensorflow:Error in loading the saved optimizer state. As a result, your model is starting with a freshly initialized optimizer.
========= sending heartbeat at 2024-01-17 20:03:30.029872
2024-01-17 20:03:31.704587: I tensorflow/stream_executor/cuda/cuda_dnn.cc:368] Loaded cuDNN version 8700
2024-01-17 20:03:31.778769: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 144.00MiB with freed_by_count=0. The caller indicates
that this is not a failure, but may mean that there could be performance gains if more memory were available.
2024-01-17 20:03:31.859603: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 150.10MiB with freed_by_count=0. The caller indicates
that this is not a failure, but may mean that there could be performance gains if more memory were available.
2024-01-17 20:03:31.859681: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 150.10MiB with freed_by_count=0. The caller indicates
that this is not a failure, but may mean that there could be performance gains if more memory were available.
2024-01-17 20:03:31.914058: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 85.06MiB with freed_by_count=0. The caller indicates t
hat this is not a failure, but may mean that there could be performance gains if more memory were available.
2024-01-17 20:03:31.914117: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 85.06MiB with freed_by_count=0. The caller indicates t
hat this is not a failure, but may mean that there could be performance gains if more memory were available.
2024-01-17 20:03:31.925992: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 153.59MiB with freed_by_count=0. The caller indicates
that this is not a failure, but may mean that there could be performance gains if more memory were available.
2024-01-17 20:03:31.926015: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 153.59MiB with freed_by_count=0. The caller indicates
that this is not a failure, but may mean that there could be performance gains if more memory were available.
2024-01-17 20:03:31.930614: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 162.81MiB with freed_by_count=0. The caller indicates
that this is not a failure, but may mean that there could be performance gains if more memory were available.
2024-01-17 20:03:31.930637: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 162.81MiB with freed_by_count=0. The caller indicates
that this is not a failure, but may mean that there could be performance gains if more memory were available.
2024-01-17 20:03:31.931428: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 290.12MiB with freed_by_count=0. The caller indicates
that this is not a failure, but may mean that there could be performance gains if more memory were available.
Running job on hostname %s lvx0959b
Allocated Resources : {‘fixed’: {‘SSD’: False}, ‘hostname’: ‘lvx0959b’, ‘lane’: ‘default’, ‘lane_type’: ‘node’, ‘license’: True, ‘licenses_acquired’: 1, ‘slots’: {‘CPU’: [0], ‘GPU’: [0], ‘RAM’: [
0]}, ‘target’: {‘cache_path’: ‘/scratch/cryosparc_cache’, ‘cache_quota_mb’: None, ‘cache_reserve_mb’: 10000, ‘desc’: None, ‘gpus’: [{‘id’: 0, ‘mem’: 25435242496, ‘name’: ‘NVIDIA GeForce RTX 3090’}
, {‘id’: 1, ‘mem’: 25438126080, ‘name’: ‘NVIDIA GeForce RTX 3090’}, {‘id’: 2, ‘mem’: 25438126080, ‘name’: ‘NVIDIA GeForce RTX 3090’}, {‘id’: 3, ‘mem’: 25438126080, ‘name’: 'NVIDIA GeForce RTX 3090
'}], ‘hostname’: ‘lvx0959b’, ‘lane’: ‘default’, ‘monitor_port’: None, ‘name’: ‘lvx0959b’, ‘resource_fixed’: {‘SSD’: True}, ‘resource_slots’: {‘CPU’: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,
14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62,
63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109
, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127], ‘GPU’: [0, 1, 2, 3], ‘RAM’: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63]}, ‘ssh_str’: ‘cryosparc_
user@lvx0959b’, ‘title’: ‘Worker node lvx0959b’, ‘type’: ‘node’, ‘worker_bin_path’: ‘/home/cryosparc_user/cryosparc/cryosparc_worker/bin/cryosparcw’}}
**** handle exception rc
Traceback (most recent call last):
File “cryosparc_master/cryosparc_compute/run.py”, line 95, in cryosparc_master.cryosparc_compute.run.main
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/run_deep_picker.py”, line 531, in cryosparc_master.cryosparc_compute.jobs.deep_picker.run_deep_picker.run_deep_picker_inference
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 830, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 835, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 755, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker._do_pick
ing
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 521, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.get_dataset_from_particle_cent
ers
ValueError: need more than 1 value to unpack
set status to failed
…I’d be grateful if you have suggestions.
Best,
Valerie
Dear colleagues,
Are there any updates on the topic?
My error is pretty similar please see below.
Many thanks.
Kind regards,
Dmitry
License is valid.
Launching job on lane default target cryotem-02 …
Running job on remote worker node hostname cryotem-02
[CPU: 211.6 MB Avail: 124.38 GB]
Job J197 Started
[CPU: 211.6 MB Avail: 124.38 GB]
Master running v4.4.0+231114, worker running v4.4.0+231114
[CPU: 211.9 MB Avail: 124.38 GB]
Working in directory: /nas/cold/cryosparc_projects/CS-katharina-110124/J197
[CPU: 211.9 MB Avail: 124.38 GB]
Running on lane default
[CPU: 211.9 MB Avail: 124.38 GB]
Resources allocated:
[CPU: 211.9 MB Avail: 124.38 GB]
Worker: cryotem-02
[CPU: 211.9 MB Avail: 124.38 GB]
CPU : [0]
[CPU: 211.9 MB Avail: 124.38 GB]
GPU : [0]
[CPU: 211.9 MB Avail: 124.38 GB]
RAM : [0]
[CPU: 211.9 MB Avail: 124.37 GB]
SSD : False
[CPU: 211.9 MB Avail: 124.37 GB]
[CPU: 211.9 MB Avail: 124.37 GB]
Importing job module for job type deep_picker_inference…
[CPU: 531.8 MB Avail: 124.15 GB]
Job ready to run
[CPU: 531.8 MB Avail: 124.15 GB]
[CPU: 547.6 MB Avail: 124.13 GB]
Using TensorFlow version 2.8.4
[CPU: 547.6 MB Avail: 124.13 GB]
Processing micrographs and inferring particles…
[CPU: 547.6 MB Avail: 124.13 GB]
Loading model…
[CPU: 547.6 MB Avail: 124.13 GB]
Loaded model.
[CPU: 547.6 MB Avail: 124.13 GB]
0/4929 micrographs processed.
[CPU: 1.07 GB Avail: 123.80 GB]
Traceback (most recent call last):
File “cryosparc_master/cryosparc_compute/run.py”, line 95, in cryosparc_master.cryosparc_compute.run.main
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/run_deep_picker.py”, line 531, in cryosparc_master.cryosparc_compute.jobs.deep_picker.run_deep_picker.run_deep_picker_inference
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 830, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 835, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 755, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.picker_extract_worker._do_picking
File “cryosparc_master/cryosparc_compute/jobs/deep_picker/deep_picker_utils.py”, line 521, in cryosparc_master.cryosparc_compute.jobs.deep_picker.deep_picker_utils.get_dataset_from_particle_centers
