Hi, I am having a problem with data processing, here is the thing.
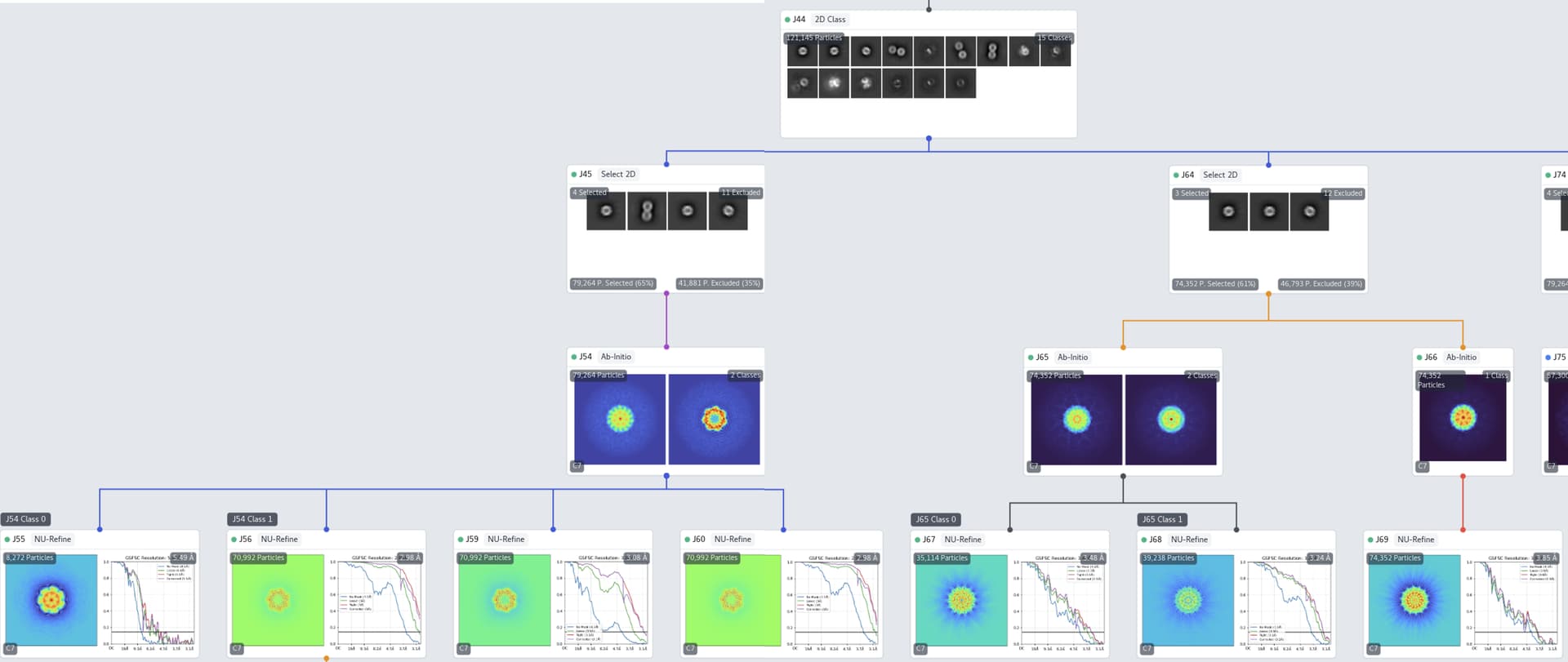
after template picking and 2D class, I select 4 different classes based on their ECA in 2D class.
I did ab-initio construction with 2 different classes. and I got a smaller class with only 8k particles and a larger one with 70k particles, and the large one refined to 2.98A.
And I thought it might be the bad particles in 2D that I included, so I did another select 2D job, which excluded the obvious outlier (the 2 blobs stacking on top of each other).
With these classes, I did ab-initio, this time, I got 2 similar sized classes, both with 30k particles. but neither of them refined to good resolution and the FSC curves are weird (they lose correlation in intermediate resolution).
I thought it might be not enough particles, so I did another ab-initio with only one class, and did refinement again, and the FSC curve is even worse.
the question I am having is this: since I got rid of one of the “bad” 2D class during select 2D job, I am supposed to get almost similar resolution, if not better. but it seems like the loss of this class completely throw off the resolution…I think there might still be some bad particles in the particle stack after I got rid of the “bad” class.
Is it possible that the “bad” class, with the 2 blobs on top of each other, can somehow function as a “seed” and “fishes out” the bad particles in the rest classes.
did anyone have the similar problem before?