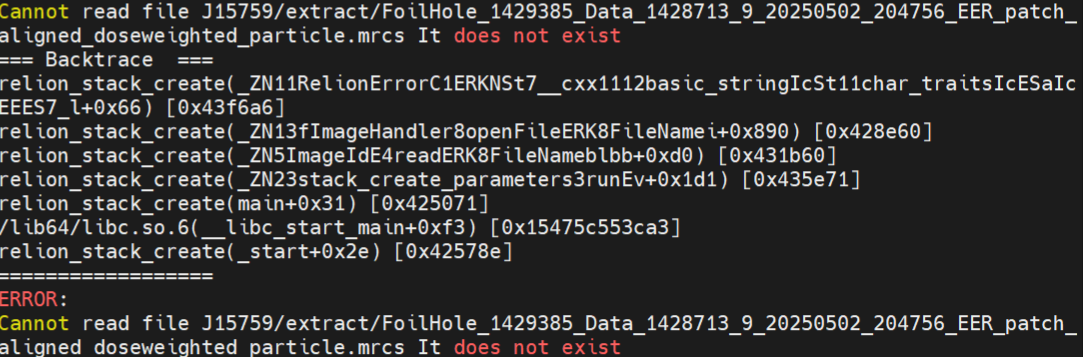
Hi @Das ,
Thank you for your reply, I got it,you’re so warmhearted.
In my understanding, firstly, Ab-initio start its reconstruction use initial parameter for many iterations by we set(eg. 200 iterations), in this processing, it find hyper-parameter for this data. In 201 iterations, it start “anneal” from initial parameter to “hyper-parameters” established by itself. then in final iterations(parameter:Number of final iterations). it use hyper-parameter to refine the reconstruction. this is the whole process right? the “Number of final iterations” starts after “annealing(also could be seen as medium process)”.
And next I want to ask about 2 things: 1: Does the number of initial iterations impact the result of classify. In other words, I want to confirm whether the parameter: “class simularity anneal start iter” and “class simularity anneal end iter” need to be set following the parameter” Number of initial iterations” and “Number of final iterations”. In my tests, class simularity anneal start iter set 300(default), class simularity anneal end iter set 350(default). Number of initial iterations set 400. In log, I found class simularity starts anneal at 300 iteration, and end at 350 iteration, however according to the principle, at the same time, the ab-initio still find its hyper-parameter, so the classify was completed by initial parameter,right? is it a good thing for classify?. logically, I think it is best for classify to make class simularity anneal in hyper-parameter(in medium process or final refine process)
Another thing is that I set initial resolution 35 A( default ), and I found the resolution increased with the iterations, For my case, I want to classify different classes in high resolution level (purpose: to find potential more solid conformation, because I still cannot reconstuct useful volume in any way by cryosparc or relion or cryodrgnai, so I want to return cs’s Ab-initio), so I set class simularity high: 0.9. and it running, running, running, I found the resolution also be higher and higher in log, and when it comes to 7A or 8A(it is optionally, and consider my case, I think it is high enough), I make it started to anneal class simularity. so in level of 7A or 8A. the class simularity start anneal from 0.9 to 0( in other words, in level of 7 or 8A, I make it start find difference in 2 different classes). and let class simularity be 0 before Ab-initio complete(I dont know when the “Number of final iterations” start, and I dont know whether I should let class simularity be 0 before final iteration start, what I can do is make class simularity be 0 before Ab job end to comfirm classifying completed). Do you think what I do is right and logically? or wheter any bug in my understanding?
best