Hi All,
I have 2 data set with different pixel size that I process separately. I would like to combine the “good” particles from the 2 data set.
How can I combine them?
Thanks,
Hi All,
I have 2 data set with different pixel size that I process separately. I would like to combine the “good” particles from the 2 data set.
How can I combine them?
Thanks,
CryoSPARC doesn’t yet support using multiple pixel sizes at once. If the original micrograph pixel sizes are the same, you can simply re-extract and match the final pixel sizes. If not, then you must find box sizes and scaling factors such that the final box sizes are the same, and the pixel sizes are within 0.01A or so.
For example, I had images with pixel sizes 1.14 A and 1.08 A, so I could use boxes of 432px and 456px, rescaling to factors of 432px. If you do the math you will see I was extremely lucky with these relative scales! There are some resources that can help if you search the CCPEM/3DEM mailing lists.
Hi,
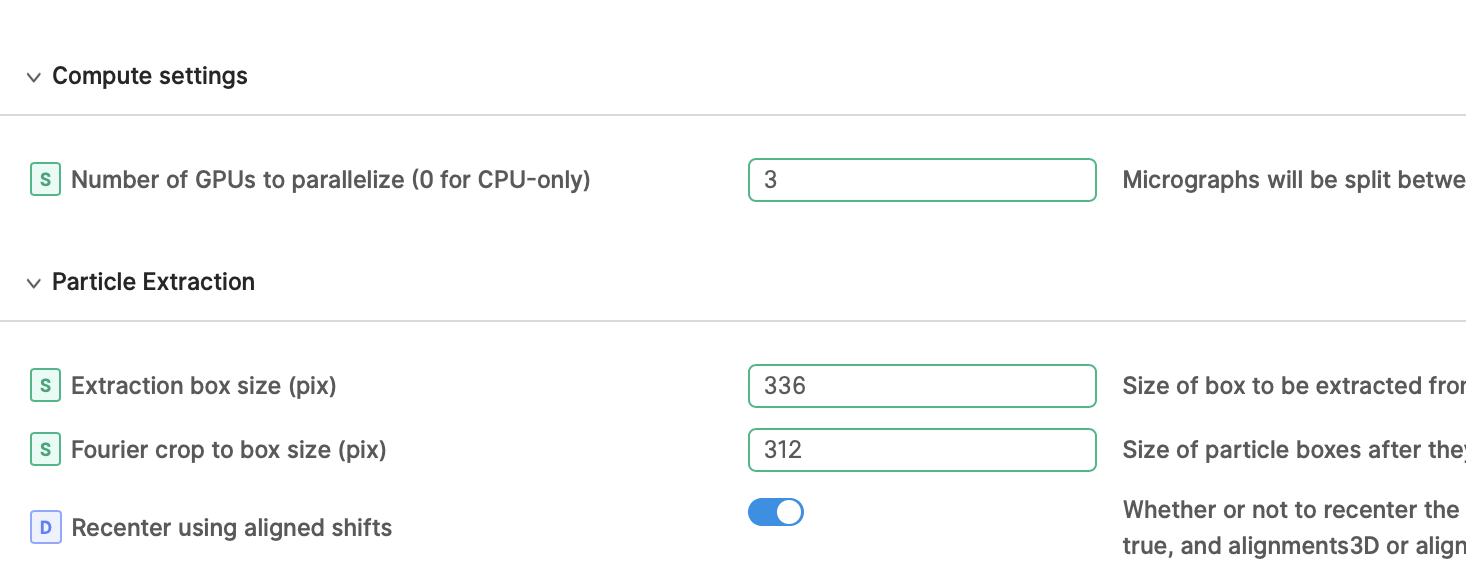
I also try to combine two dataset( tilted and untilted) with different pixel size( 0.98 and 0.91), I rescaled the 0.91 one with 336 box size to 312 so that it gives me 0.98 final.
I don’t know why you have this normalization issue; maybe it has something to do with the way scales are computed in 2D.
Here is the mailing list post I mentioned earlier:
hi,
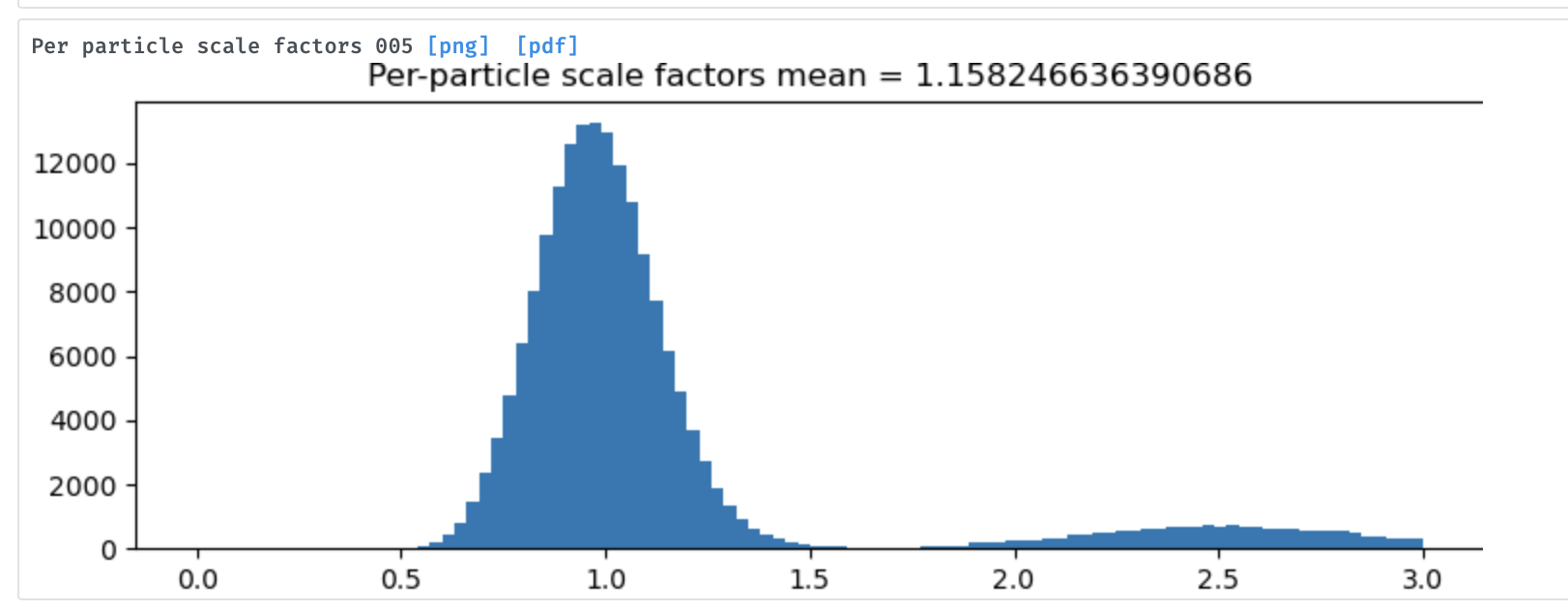
thanks, I did a refinement and found that the scale has two populations. Do you know how the scale is used in cryosparc?
Hi @zhenyu_tan,
2D classification does not compute or use per-particle scale factors. Thus for the tilted + untilted data if the tilted images are significantly “dimmer” than the other due to ice thickness or angle of incidence, there will be a difference in scales. This is what the refinement job has detected. The refinement job computes and then uses the optimal per-particle scales in alignment and backprojection
Thanks for your answer. I am curious how the scale been optimized during refinement? I did not find it was described in the paper.