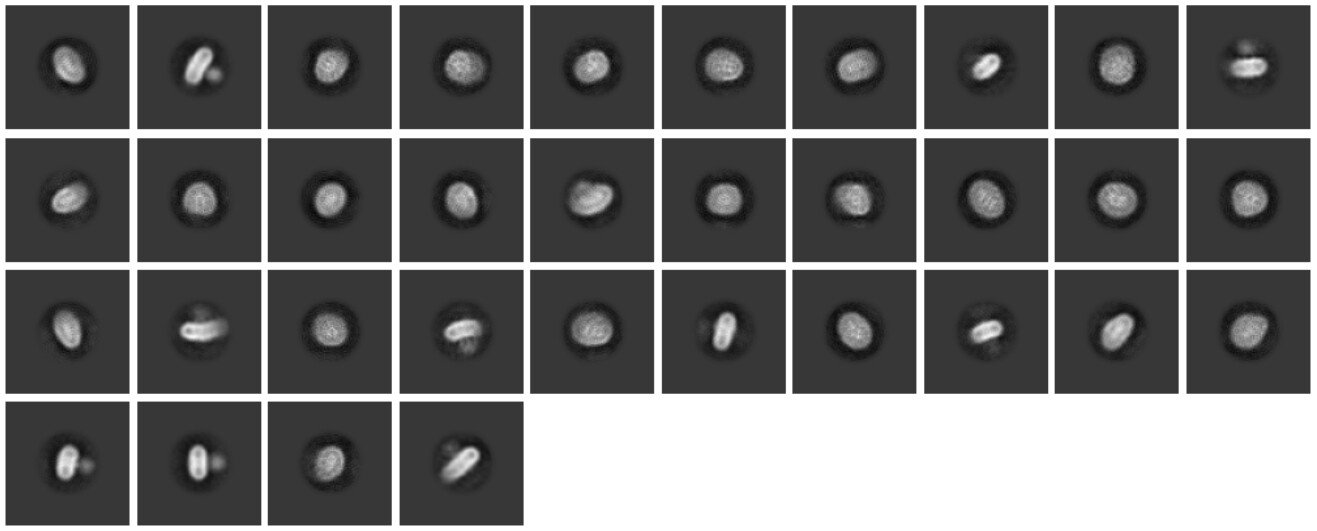
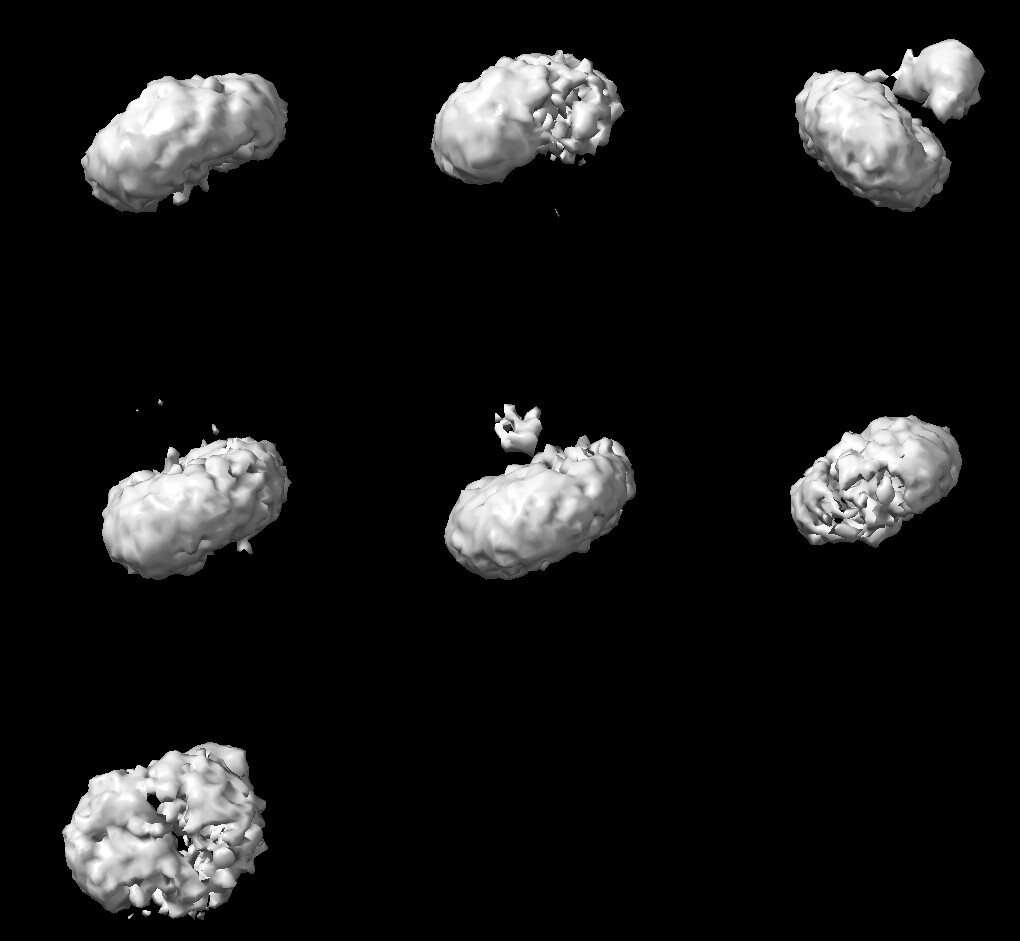
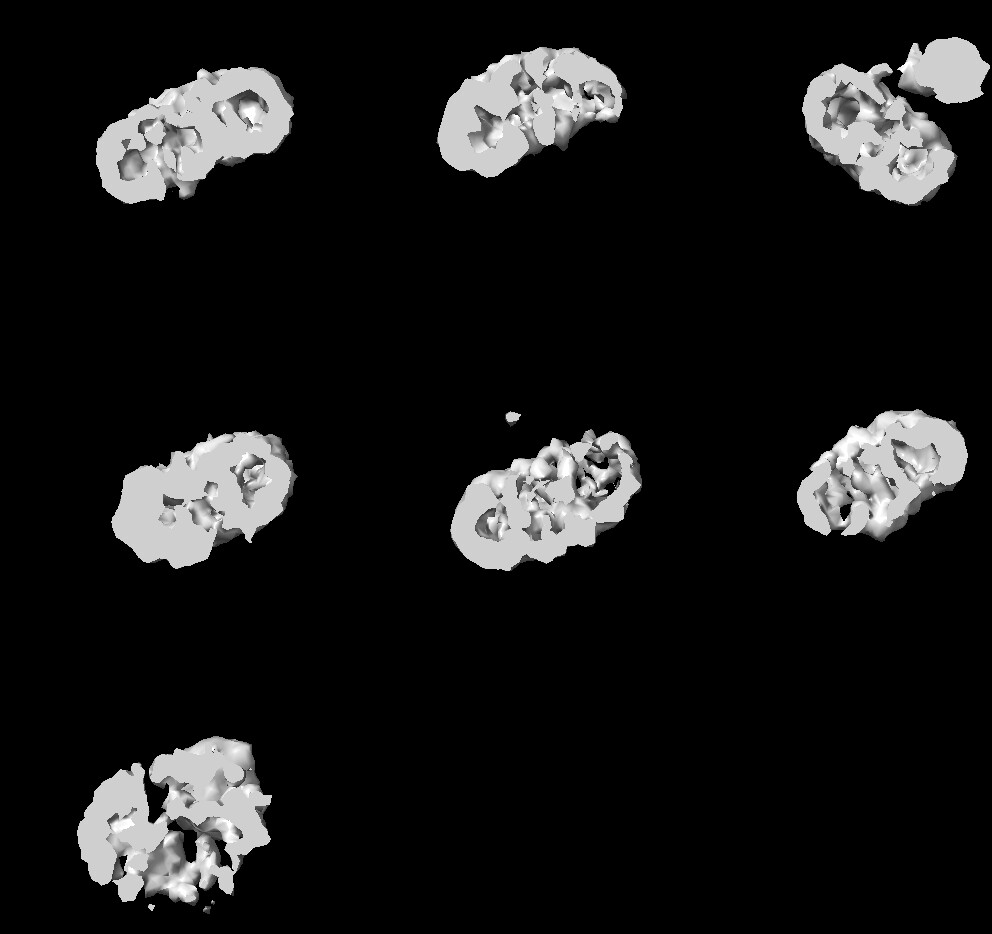
I ran ab initio to create an initial model and get rid of junk particles. I changed the following parameters:
Number of ab initio classes: 7 Maximum resolution: 7 Initial resolution: 10 Initial mini batch size: 300 Final minibatch size: 1000 Class similarity: 0
When I run the ab initio job, I get 7 similar classes, meaning they look like a particle or a micelle. like in this picture:
When I read the literature, I notice that in every paper they run ab initio and succeed in separating the junk from real particles because they state: [we got “Junk classes” which we removed].
I am wondering if my ab initio is converging too soon (if this makes sense) and if there is a parameter I can tweak to circumvent this problem. I am now running heterogeneous refinement with the volumes I got from ab initio to see if I can get rid of the junk particles.
I have also faced the same problem when I did 3D classification on a different set of particles.
Does anyone have any suggestions on how to get rid of junk during 3D ab initio reconstruction or any other way? I would be grateful.
run again with 2, 3, 4, 5 classes. I use ab initio simply to generate a good reference for future jobs. I do not use it as a selection criteria for good/bad particles, though that seems to be what several do. Instead, do what is possible to get a good initial model, and clean up with heterogeneous refinement, providing 1 good and 5 bad models, or half/half, or 1 junk and 5 good models etc. Often using several “good” models of varying preferred orientation or resolutions will also be successful in tricking the het refine to securing 1 very good class.
You can also just take the best/best 2-3 particles sets, and run a new ab-initio with them to get a better model, and repeat. Once I got my good initial model with just 20k particles, then I used heterogenous refinement to sort out particles that I have previously discarded too.
To circumvent too early convergence, you can set “Number of initial iterations” to something like 1000.
Thank you @CryoEM2 for your response. I will give it a try to clean up with the het-ref. Do you mind elaborating on what you meant by “using several “good” models of varying preferred orientation”? Did you mean deliberately choosing particles that pertain to a certain view then creating a model with it and use it as a volume in het-ref?
Thank you @MLiziczai for responding. That was my previous strategy but it didn’t help much either. I will try your suggestion about increasing the initial number of iterations.
Let me know how it goes.
I found that having nr. of initial iterations below 500 does nothing, and although I also change the nr. of final iterations to 1000, I find it less important. And I have seen far larger numbers then 1000 work too. Just be aware, that it takes very long to compute (depending on the particle numbers and number of final iterations).
Mostly yes. By running ab initio and her refine several times, I typically end up with a couple classes that contain mostly just one preferred view, and the 3D volume of course has extreme anisotropy. Using this as a reference or a few references can sometimes act as a sink to dial out the overrepresented particle view, making the remaining particles have a better chance to develop a good 3D
I’m not sure if this is the best place for this question, but if using ab initio to sort (I am going to try both using ab initio and using het refine), if you want say 3 classes and expect 2 to be different conformations and 1 to be junk, what would you set for the class similarity parameter? When using ab initio for generating an initial model, what do you normally set for that parameter? I’ve tried it a bunch of different ways and don’t notice a huge difference myself but I’m interested in what others think.
I try to force good euler distribution with select2D and then build a single initial model and then use that + junk in het refine to build an even better looking model and identify all particles from all views that align to it. then move on to heterogeneity sorting with advanced tools.
If I have to use multi-ab initio then I typically set class similarity to 1 so all classes try to make a very similar model. If it is set to 0.1 then the models will generally derive from the particles of a single view (can run 2D of each set of particles and confirm), and when people then use all of these ab initio models as inputs to a single het refine job, they sort all of their particles into bins based on view and never build a good model comprising all views. this is a likely source for way more preferred orientation observed in datasets than actually exists..