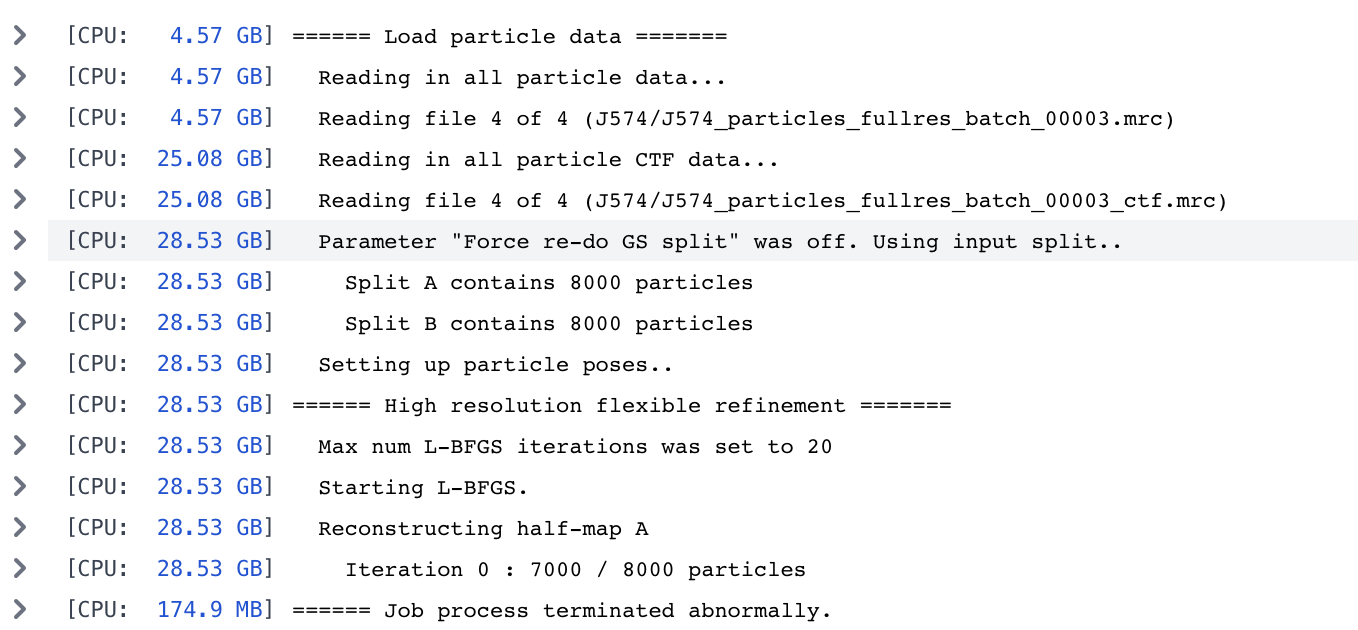
I was running 3D flex refinement on a smaller dataset (box size 400, particle number 9K), and it ran through. I would like to try an unbinned dataset with more particle (box size 506, particle num 16K). At first, we are not able to run because of memory issue, after we add more memory to GPU, it can run but got terminated in the middle, give us the following message:
This may be worth confirming with reference to the cluster job historic records/logs.
I wonder if increasing the #SBATCH --mem= option from the current configuration (how? 1, 2) might help?
We tried on a node with 256GB RAM and RTXA6000 46GB RAM. It failed with python error (probably because it was running on AMD EPYC ?)
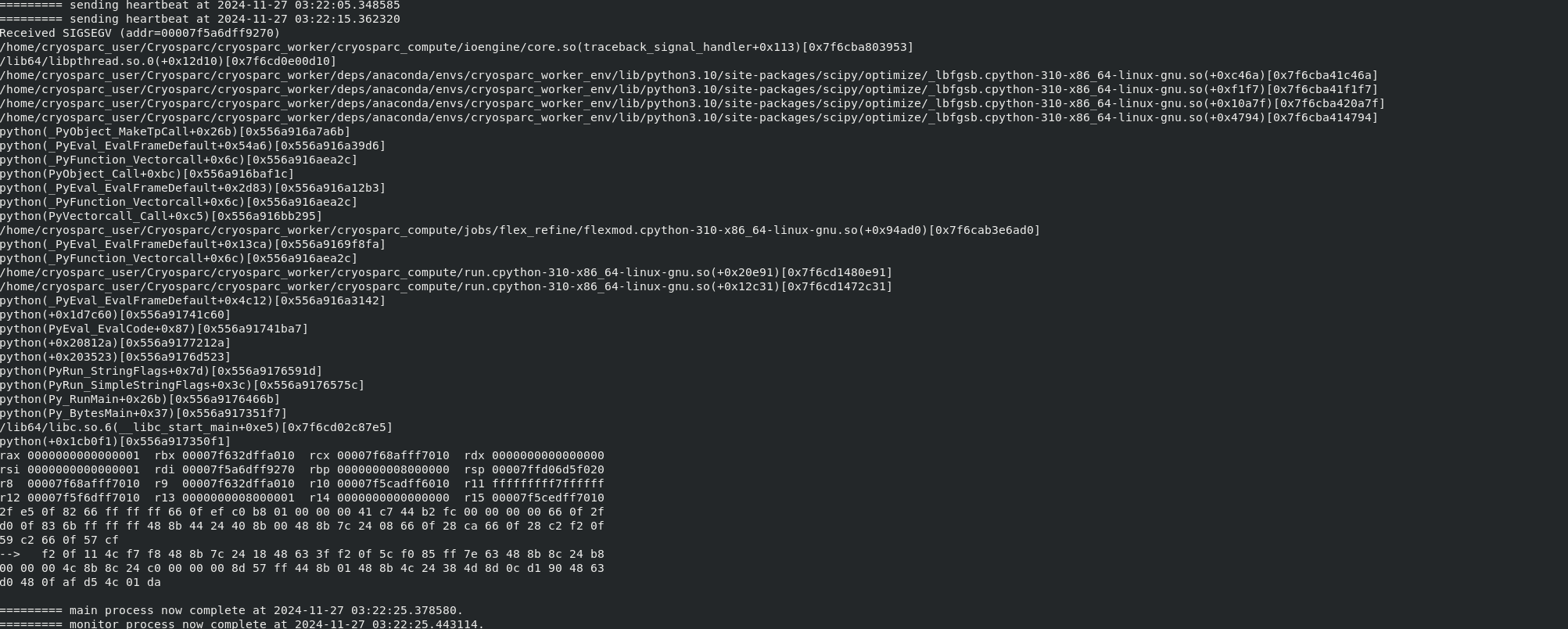
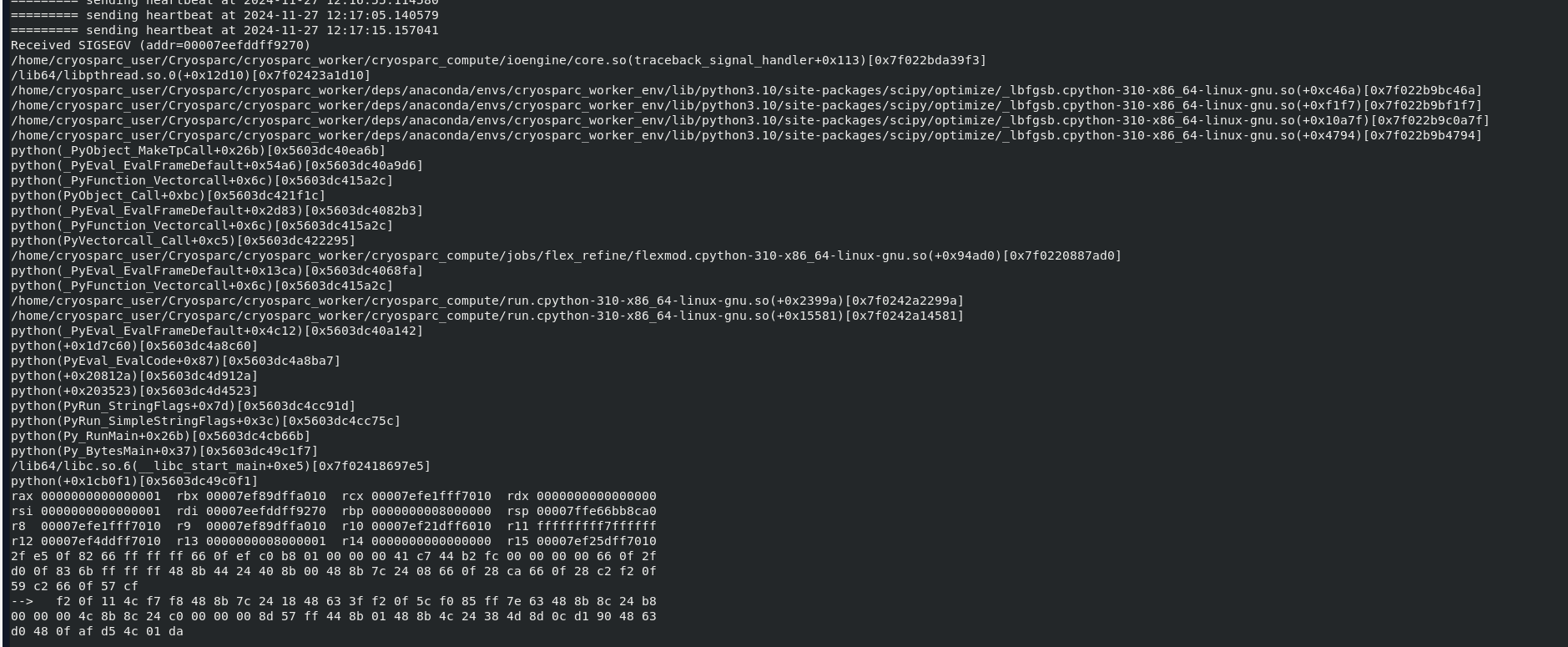
Here are the error message:
/var/log/messages-20230903:Aug 30 11:05:15 nodeb319 kernel: python[28860]: segfault at 7f3ff9ca0df0 ip 00007f5a2b5e8ff8 sp 00007ffcfff3a410 error 6 in _lbfgsb.cpython-38-x86_64-linux-gnu.so[7f5a2b5d9000+17000]
Your cluster manager may kill a job if that job exceeds the (possibly much smaller) RAM size specified by the #SBATCH --mem= option inside the cluster script. This may not be the root cause, but I would like to see this possibility eliminated first.
The name of the library suggests a connection to the job. I will check with our team about this lead. The timestamp of this kernel message does not match the timestamp of the abnormal job termination as closely as I would expect, even allowing for possibly different time zone conventions of the timestamps.
A brief update: The Structura team has seen segmentation faults in 3DFlex like the one you described before. Unfortunately, we have not yet established a pattern that would help us identify the root cause, which may be related to the platform on which a job is running. Do you have access to other compute nodes with, perhaps, a different x86-64 CPU model or a different OS (or OS version) where you could try the job?
Also ensure that your cluster script template does not restrict RAM usage more tightly than you intended.
We are experiencing this issue also on a stand alone machine with 500 gb RAM and 4 NVIDIA GeForce RTX 3090 GPU cards with 24 gb memory.
OS: Cent OS Linux 7
Kernel: Linux 3.10.0-1160.71.1.el7.x86_64
We are running CryoSPARC v4.5.1
At 520 box size we see the job process terminated abnormally message.
The stack is quite large as we symmetry expanded (900k). However, this doesn’t seem to be related to particle number, as running the flex reconstruct on a 10k subset also fails in the same manner.
From a similar thread it seems box size can be the issue. Using the binned blob from flex train (128 pix), the flex reconstruct runs fine. And very encouraging is the GSFSC curve, suggesting we have a lot of resolution to gain once we unbin.
So we have attempted 2x Bin (260 box) and this works!
But ultimately, it would be great to run this without binning as from what I can tell, this particle is a perfect use case for Flex Refine and initial results are very promising! We’re testing some tighter cropping of the particle and hopefully this will help…
Any further suggestions on this topic? Or would any more information on our end help?
Hello @wtempel,
I seem to be experiencing a similar error, could you help me fix it ?
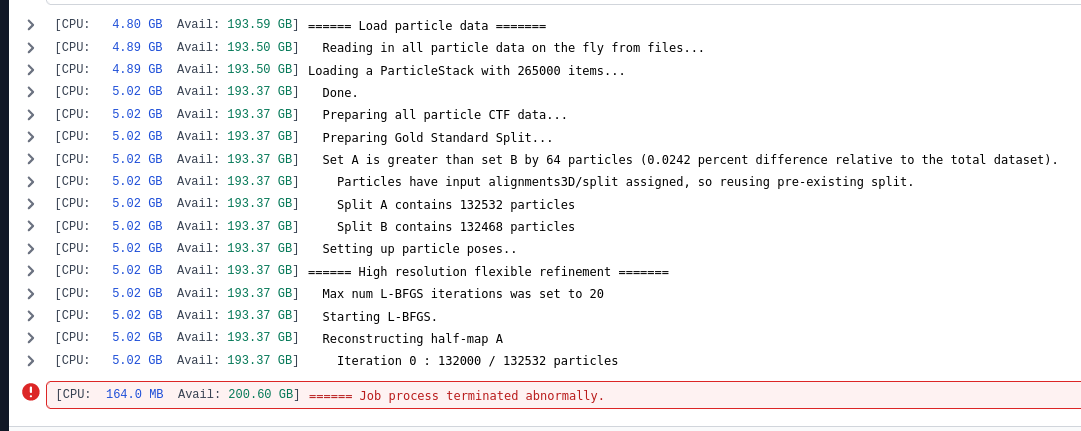
I’ve been working with 3D flex for the past few week, and after finding a process i was happy with with a lower resolution (box size=256, pxl size = 2.12). I decided to reproduce it at a higher resolution (box size=512, pxl size =1.06). I did my data flex train setting the training box size at 256 (half the original box size), i did the same custom mesh as usual from a segmentation and the neurla network training worked.
My data set has 300k particule and i made sure nothing else was running when i tried.
but when i do the 3d flex reconstruction this is what i get.
It’s part of systemd, which CentOS 7 uses. However, to access it, you need root permissions.
Or you can allow your user to access journalctl with a command similar to usermod -a -G systemd-journal [username] - as root user, if institutionally controlled, the policy may be “not a chance” on allowing this for normal users.
@Yannlefrancois We have found that there is an issue with 3DFlex reconstruction above box size 440, but that we do not yet know the root cause or a workaround that accommodates the larger box size. See Flex Reconstruction Failing - #4 by hbridges1 for a workaround using a smaller box size.