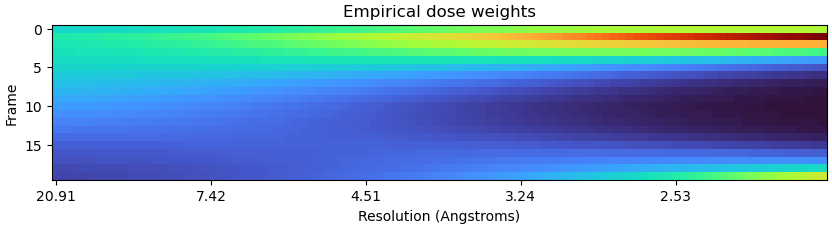
There is little public data available from Apollo detectors. Had a GPU free so decided I’d have a quick look and see whether they demonstrated the high late-frame dose weighting (as many with K2/K3 data report) or the lower overweighting I see with our Falcon data. I’ve found one dataset which has “bad” overweighting in the late frames from our Falcon and it’s nowhere near as bad as demonstrated by data reported by others with K2/K3s.
EMPIAR 11261 (the high dose rate dataset) is the only one with RBMC output right now:
Run with defaults, except “extensive” for hyperparameter search. This overweighting is a bit worse than the absolute worst I’ve seen from a Falcon 4, but nothing like that demonstrated by others. I’ll check the lower dose rate data also as time permits.
Wish I knew why sometimes the RBMC plots are short while other times they’re significantly longer. Doesn’t seem frame count related…
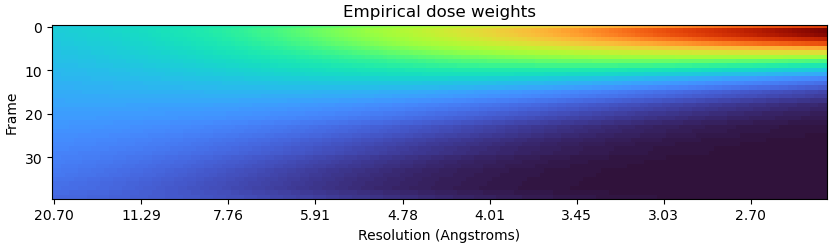
For a ryanodine receptor dataset (2.4MDa particle with a lot of signal) we see very modest overweighting of late frames on K3 compared to what we see for smaller (<200kDa) particles:
So clearly a correlation distance of 500 is not optimal for all samples.
(In this case global res improved by 0.15Å with RBMC)
Side note - @hsnyder it would be helpful I think to have some per-resolution dose weight vs frame line plots in this output. E.g. dose weight vs frame at 4Å, for example. This would make it a lot easier to judge the shape of the dose weight curve than trying to eyeball the difference between dark blue and light blue on this plot…
In the meantime are the weights written anywhere where they can be replotted with CS tools?
I’ll check a few virus runs; they’re a bit larger (at least in terms of total MW). Don’t have any giant virus (GDa scale) K3 data, but do have some AAV at around 5MDa. Will need to dig through offline backups though.
…
I have a tangentially related question; I’m running RBMC on some focussed refinements and extensive hyperparameter calculation is taking forever (3.5 days so far with no sign of finishing) and as such I’m loathe to repeat hyperparameter calculation for each area. I think dose weights would be safe to re-use (it’s the same dataset after all) and hyperparams should also be safe to re-use (again, same dataset) - it would save a lot of time rather than have to re-run steps 1 and 2 of RBMC another four times. In a brief test run with a smaller dataset, I got the same hyperparams between three different runs, but, much smaller dataset, much smaller particle.
Opinions on just using params and dose weights (if sane) from the first run on the others?
Side note - @hsnyder it would be helpful I think to have some per-resolution dose weight vs frame line plots in this output. E.g. dose weight vs frame at 4Å, for example. This would make it a lot easier to judge the shape of the dose weight curve than trying to eyeball the difference between dark blue and light blue on this plot…
This sounds like a useful idea, thanks @olibclarke I’ll record this.
In the meantime are the weights written anywhere where they can be replotted with CS tools?
Yes. The hyperparameters output group contains a refmotion_doseweights/path column which will tell you what file to load to get the actual dose weights. It’s a simple array with shape (frame, box size).
Opinions on just using params and dose weights (if sane) from the first run on the others?
@rbs_sci, I’d say it’s definitely worth a try. I’d be interested to hear your findings, but in my experience getting the parameters “in the ballpark” often gets you most of the total improvement, and the optimization landscape is somewhat consistent across datasets. There are exceptions to that, but IMO it is worth a try.
Honestly, depending on the SNR, I think there are many cases where the parameter tuning really isn’t that precise/sensitive anyway. There’s definitely some room for an improved model in the future, but with the current one, sometimes frames are just so noisy that once you get “similar-ish”, it’s hard to know which of any two sets of hyperparameters is really “better”.
@olibclarke@rbs_sci is it correct to summarize your results/best practices findings to date as follows? Were there any cases where a different parameter correction was needed to fix dose weighting?
If late-frame overweighting is seen (nonmonotonic weight decay at high res) in 1st RBMC job, re-estimate empirical dose weights using 10x lower spatial correlation in 2nd RBMC job
Run motion correction using original hyperparameters via manual entry but link hyperparameters with dose weights from 2nd RBMC job
Yep, that is what we do. Still not entirely clear that it fixes dose weighting completely, but it does more or less eliminate the incorrect upweighting of later frames.
Thanks both. It occurs to me that it should be pretty much impossible for overaggressive dose weighting to limit resolution. All the good high res signal is in the early frames, and faster weight decay should just begin to reduce the amount of low res signal being pulled from later frames. Simultaneously, only quite small total doses are needed for reconstruction, and often for local and even global search as well. (I’ve found that < 4e-/A^2 is sufficient for from-scratch refinement of CoV Spike trimers for example, while < 1e-/A^2 is enough for reconstructions).
Should we even try to rescue more low res signal unless we know it’s a limiting factor? Maybe fixed dose weights that reach ~0 by 2-5 e-/A^2 would work even better, especially for local search or reconstruction only. @hsnyder a related feature request would be to set a maximum total dose or number of frames for particles from RBMC.
Hi @DanielAsarnow! You may already be aware of this, but in case others are interested, we’ve actually found that the greatest improvement from empirical dose weights comes when the first frame is not the best. So while you’re right that in general we expect relatively little improvement from playing with the exact weight of the late frames, finding the correct weight from the early frames can make a significant difference in samples with high in-frame motion. This improvement wouldn’t be captured by simply limiting the total dose.
@rwaldo thanks that’s interesting! Do you have data on the frame dose for those datasets? And do you have any data on the relative contribution of particle trajectories vs. empirical weights?
Based on Shawn’s past MotionCor2 benchmarks we thought throwing away the 1st frame entirely was useful when then frame dose was ~1 e-/A^2 or greater. I usually shoot for ~0.5 e-/Å^2/fm. In addition to the motion part, even 1e-/A^2 will break disulfides…
Also to be clear I’m mainly worried above about late frame weights causing noise to be injected. I would also be interested in empirical weights that clamp to zero after a certain dose (combining your point and my previous request), and any other feature supporting differential total dose reconstructions.
I didn’t run these tests myself so don’t know all the datasets used, but least the ones for the guide pages were ~ 1 e-/Å^2, perhaps confirming your suspicions
In our tests, when RBMC makes a difference overall approximately half of the improvement comes from particle trajectories and half from dose weights.
@DanielAsarnow do you have a reference for this (re disulfide breaking at low dose)? Anecdotally we have observed the same and were surprised when even first-frame reconstructions (at 1.2e-/Å2/fm) showed broken disulfides
I’m a little puzzled, though, as I have a sample at the minute which has quite a few disulphide bonds evident, and while a few of them could be described as weak… most look to be in good shape, even with the full dose (50 e-/A^2). And given their location, I’m more inclined to think it might be minor structural heterogeneity than explicit breakage…
But another (smaller mw) sample shows signs of damage in the disulphides similar to that discussed in Hattne et al, so… hm.
That said, if damage is occurring before the first e-/A^2 is complete, the only remedy is single-frame reconstruction or zero dose extrapolation, as whether you hit the sample with 10e or 60e won’t make the blindest bit of difference…
@olibclarke@rbs_sci Yes, Hattne 2018 would be my formal reference, but I really take it from a personal experience with never-published SPA data of a bacterial ABC transporter. We had used a MC/MC approach to model disulfide introductions that could trap a certain conformation. The mutations were successful, total crosslinking evidenced by reducing vs. non-reducing SDS-PAGE, and delivered a very nice structure of that (hitherto unobserved) state. The new cysteines were clearly resolved and well within DS bonding difference…but facing away from one another! We did reconstructions with doses down to 1 or 2 frames at ~1e-/Å^2 but never saw an intact bond.
Dose fractionation works! Really hard to predict because it’s dependent on the strength of the disulfide, precise efficacy of dose fractionation, electron energy, and possibly sample factors (if ROS generation/water activation is involved). A DS might be intact only in the first frame, but the first frame is then corrupted by the first-frame motion problem. Then perhaps it could never be recovered.
Very interesting - we saw the same with bovine thyroglobulin. We even collected some hexaufoil data and did first frame reconstructions (I would need to check the dose per frame) but we also saw similar - disulfides that we know ought to be there, broken..
Yup. About to submit a manuscript to the IUCrJ special issue later today (cutting it tight! ). When I’ve done that and dealt with some other stuff, I’ll pop it up on bioRxiv as well, as it may be of interest…