So i performed forcedeps and I am getting this during particle extraction with v4.1.1
Error occurred while processing micrograph J712/motioncorrected/002609194105202031183_FoilHole_12530805_Data_12522960_12522962_20221212_180445_Fractions_patch_aligned_doseweighted.mrc
Traceback (most recent call last):
File "/opt/cryosparc/cryosparc_worker/cryosparc_compute/jobs/pipeline.py", line 60, in exec
return self.process(item)
File "/opt/cryosparc/cryosparc_worker/cryosparc_compute/jobs/extract/run.py", line 498, in process
result = extraction_gpu.do_extract_particles_single_mic_gpu(mic=mic, bg_bin=bg_bin,
File "/opt/cryosparc/cryosparc_worker/cryosparc_compute/jobs/extract/extraction_gpu.py", line 143, in do_extract_particles_single_mic_gpu
ifft_plan = skcuda_fft.Plan(shape = (bin_size, bin_size),
File "/opt/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/fft.py", line 132, in __init__
self.worksize = cufft.cufftMakePlanMany(
File "/opt/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py", line 749, in cufftMakePlanMany
cufftCheckStatus(status)
File "/opt/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py", line 124, in cufftCheckStatus
raise e
cryosparc_compute.skcuda_internal.cufft.cufftAllocFailed
Marking J712/motioncorrected/002609194105202031183_FoilHole_12530805_Data_12522960_12522962_20221212_180445_Fractions_patch_aligned_doseweighted.mrc as incomplete and continuing...
more update. the error for not processing some of the images persist even after executing forcedeps on the worker. All images are processed if i revert to v4.1.0.
I am getting a similar error trying to extract particles with v4.1.1
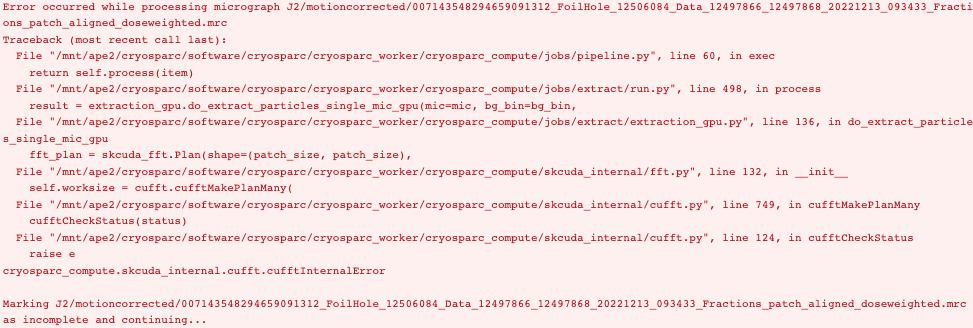
Many micrographs fail with the following error:
Error occurred while processing micrograph S5/motioncorrected/FoilHole_13208278_Data_13091718_13091720_20200814_153325_fractions_patch_aligned_doseweighted.mrc
Traceback (most recent call last):
File “/scratch/cryosoft/cryosparc/cryosparc_worker/cryosparc_compute/jobs/pipeline.py”, line 60, in exec
return self.process(item)
File “/scratch/cryosoft/cryosparc/cryosparc_worker/cryosparc_compute/jobs/extract/run.py”, line 498, in process
result = extraction_gpu.do_extract_particles_single_mic_gpu(mic=mic, bg_bin=bg_bin,
File “/scratch/cryosoft/cryosparc/cryosparc_worker/cryosparc_compute/jobs/extract/extraction_gpu.py”, line 136, in do_extract_particles_single_mic_gpu
fft_plan = skcuda_fft.Plan(shape=(patch_size, patch_size),
File “/scratch/cryosoft/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/fft.py”, line 132, in init
self.worksize = cufft.cufftMakePlanMany(
File “/scratch/cryosoft/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py”, line 749, in cufftMakePlanMany
cufftCheckStatus(status)
File “/scratch/cryosoft/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py”, line 124, in cufftCheckStatus
raise e
cryosparc_compute.skcuda_internal.cufft.cufftInternalError
Marking S5/motioncorrected/FoilHole_13208278_Data_13091718_13091720_20200814_153325_fractions_patch_aligned_doseweighted.mrc as incomplete and continuing…
I am getting the same error during particle extraction (with slightly different error message):
Error occurred while processing micrograph J1/imported/015139662710773897517_FoilHole_7700328_Data_7666634_7666636_20221208_055455_EER.mrc
Traceback (most recent call last):
File "/home/changliu/Applications/cryosparc/cryosparc_worker/cryosparc_compute/jobs/pipeline.py", line 60, in exec
return self.process(item)
File "/home/changliu/Applications/cryosparc/cryosparc_worker/cryosparc_compute/jobs/extract/run.py", line 498, in process
result = extraction_gpu.do_extract_particles_single_mic_gpu(mic=mic, bg_bin=bg_bin,
File "/home/changliu/Applications/cryosparc/cryosparc_worker/cryosparc_compute/jobs/extract/extraction_gpu.py", line 143, in do_extract_particles_single_mic_gpu
ifft_plan = skcuda_fft.Plan(shape = (bin_size, bin_size),
File "/home/changliu/Applications/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/fft.py", line 132, in __init__
self.worksize = cufft.cufftMakePlanMany(
File "/home/changliu/Applications/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py", line 749, in cufftMakePlanMany
cufftCheckStatus(status)
File "/home/changliu/Applications/cryosparc/cryosparc_worker/cryosparc_compute/skcuda_internal/cufft.py", line 124, in cufftCheckStatus
raise e
cryosparc_compute.skcuda_internal.cufft.cufftInternalError
Marking J1/imported/015139662710773897517_FoilHole_7700328_Data_7666634_7666636_20221208_055455_EER.mrc as incomplete and continuing...
As I wrote in another post, this error seems to be related to GPU out of memory, because I noticed that the used GPU memory was about 5 GB when the job was initially launched and gradually increased as the job ran. Eventually, as one or more of the GPUs ran out of memory, I started to see the error messages. Using the CPU version of the job, particle extraction successfully completed for all the micrographs without any issue. And the system memory usage stayed about the same through the whole process of the job. It seems like the GPU version of the particle extraction job was unable to release the GPU memory after it finished extraction from previous batches of micrographs.
Just an update: the new guide for installation now has this new requirement
“Nvidia driver version is 460.32.03 or newer on all GPU machines. Run nvidia-smi to verify”
We have 3 workstation, the one machine that fullfil this requirement and CUDA 11.7 (plus other listed requirements) is giving no error. We are in the process of updating the nvidia drivers on the other workstations and will test if that is what we were missing.
Hi @Bassem, thanks for sharing this information. We actually already have relatively new versions of Nvidia driver (520.61.05) and CUDA (11.8) installed in both of our workstations that gave this error.
Another thing I noticed is that the error generally happens when the extraction job reaches 2000-3000 micrographs. This is also when my GPU runs out of VRAM (24 GB). So depending on the amount of VRAM your GPUs have, you may not have this error, especially if you extract from a relatively small dataset. But I would definitely be interested in knowing if updating the nvidia drivers on the other workstations you have solves this error.
The update on the other machine did not help with the error during particle extraction
I tried to keep an eye on the GPU memory. With v4.1.0 the max usage I noticed on any given GPU during that job is ~7GB/24GB while with v4.1.1 it went all way up to 19-20GB/24GB doing the same job. I do not know what that means, I am stretching my nerdy computer self here.
I downgraded the cryosparc to v4.1.0. Now the particle extraction job can finish without an issue. The GPU memory usage stayed about the same (~7-8 GB, consistent with what you observed) through the whole process of the job.
Can you please provide us with: nvidia-smi uname -a
Whether you ran cryoparcw install-3dflex or not
the instance_information field from the failing job’s metadata
3- Linux spgpu 3.10.0-1160.49.1.el7.x86_64 #1 SMP Tue Nov 30 15:51:32 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
4- instance information → that was deleted by the user when we rolled back to v4.1.0 but i have the entire job report folder which part can i share with you?