This thread helped me a lot as well:
I did local refinement with the parameters recommended by @olibclarke there and proceeded with 3D Classification.
The 3D classes looked very promising:
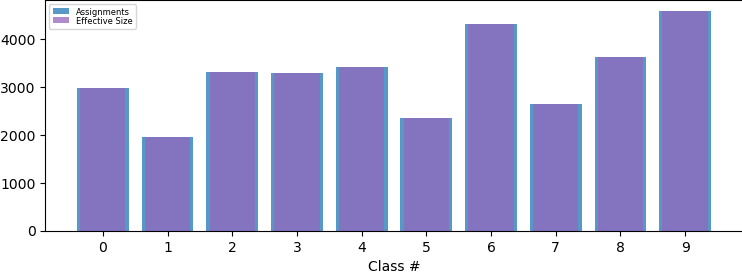
Fig 1: Class distribution
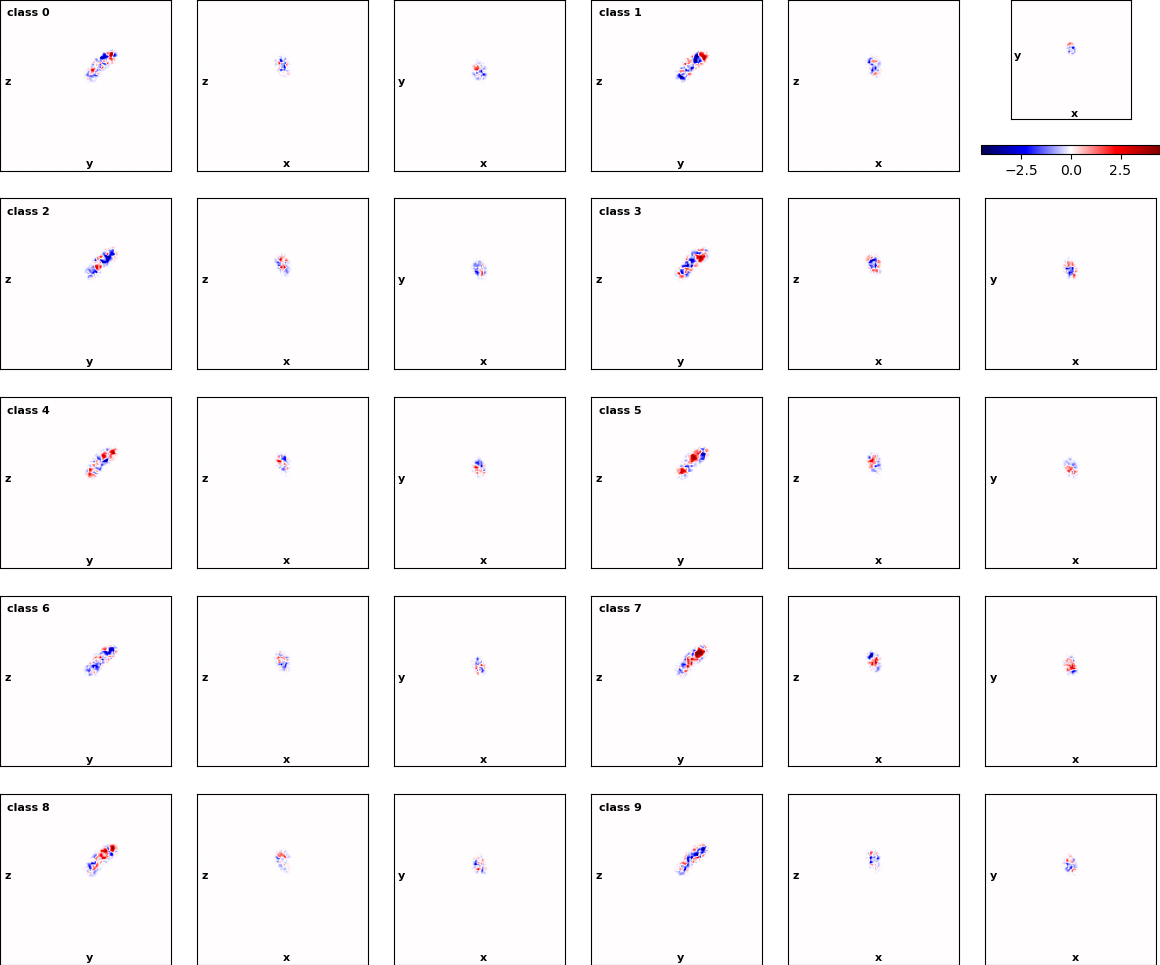
Fig 2: Real-Space Difference from Consensus with Focus Mask
Specially class 7. However, when I did Non-uniform refinement I didn’t have great improvement in the resolution of the density inside the mask. I think the problem is related with the final number of particles present in the reconstruction rather than the processing workflow. Probably there is still room for improvement and I will give a try to your suggestions.
Thank you very much for all the help.
Best,
Nuno