sometimes I will submit multiple jobs to the queue (for example, multiple 3D refinements or 2D classifications with various settings changed to see which works best). I’ve noticed recently that more GPU-dependent jobs will run than the current number of GPUs. I submitted 7 refinement jobs and all were running simultaneously on a 4-GPU machine.
While this hasn’t caused any jobs to fail yet, I am nervous when multiple users start using the queue. Right now I am the main user.
Is this a feature or a bug? Is cryoSPARC deciding that multiple jobs can run on a single GPU, or is this a misallocation of resources and it will eventually cause a problem? Is this a problem with the install?
Thanks!
Rick
cryoSPARC version: v2.15.0
CentOS 7
4x TX 2080 Ti GPU, 64 cpu cores, 256 GB RAM
If you’re using the "Queue directly to a GPU" modal, cryoSPARC will allow you to override the scheduler and execute the job immediately on the GPU you’ve selected, regardless of whether the machine has enough CPU or RAM resources available.
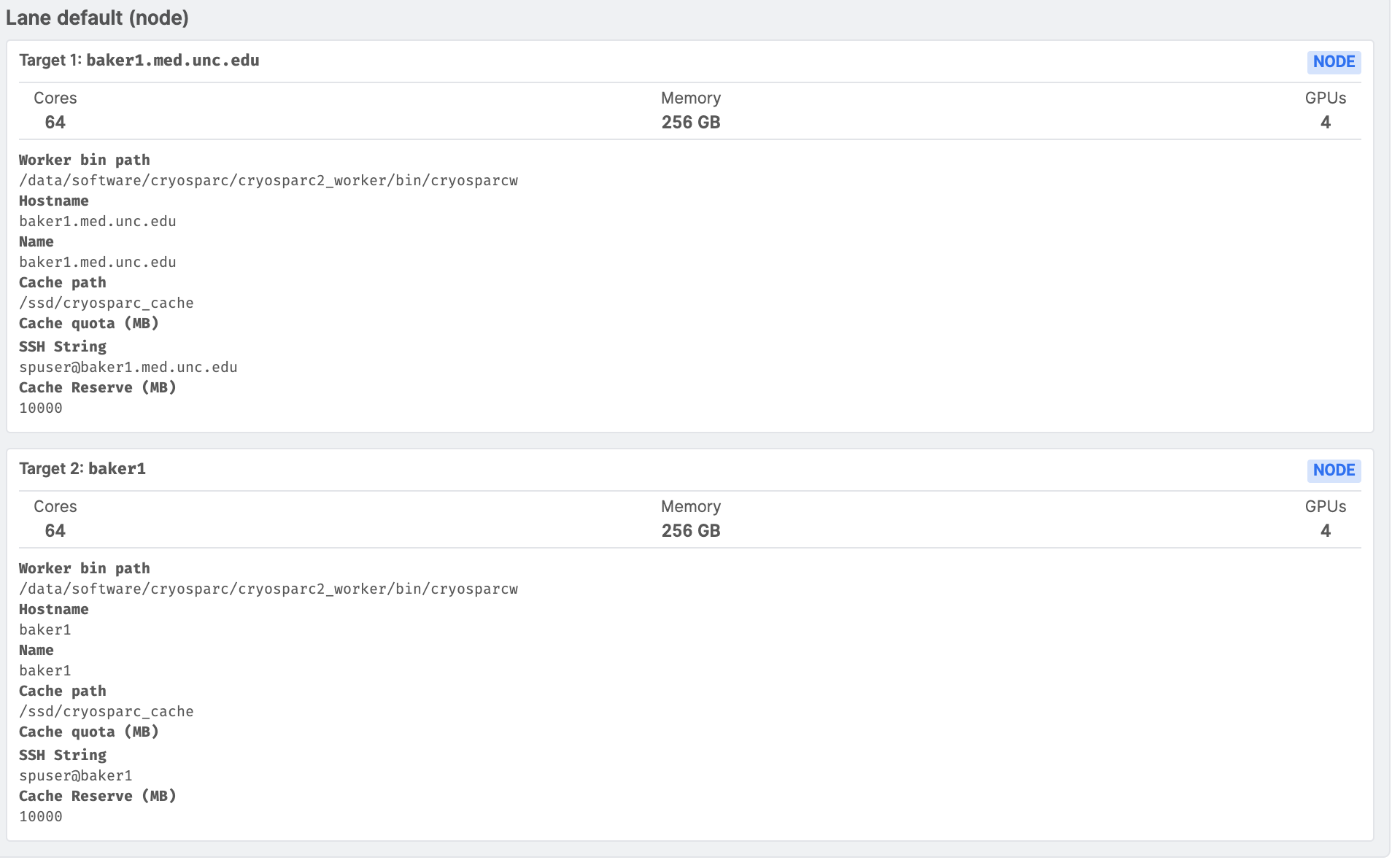
Otherwise, if you’re using the regular lane-based scheduling, the scheduled jobs should be adhering to the CPU, RAM and GPU resources available. Can you send us a screenshot of your Resource Manager when this happens? Can you also send us a screenshot of the “Instance Information” tab?
I wasn’t queuing directly to a GPU, but simply putting in the default queue lane. However, when I looked at the resource manager tab like you suggested, it seems like I have multiple workers/nodes. I guess this means that the master thinks that it has more resources than are actually there.
Looking at past posts, I used this command to remove the extra node.